CMU15-213
本篇主要记录在学习课程CMU15-213(version:sp23)以及配套教材CS:APP中的总结、梳理、拓展以及个人感想。
Lab部分会记录解题思路在另外部分。
Overview
对应CS:APP第一章
让我们从详细理解一段代码的生命周期开始深入了解计算机在这一过程中完成了哪些操作。
1 | |
hello程序的生命周期是从一个高级的C语言程序开始的,但是在机器执行时需要将这些语句转化为一系列的低级机器语言指令。然后这些指令按照一种称为可执行目标程序的格式打包,并以二进制磁盘文件的形式存放起来。
通过一条指令 gcc -o hello hello.c ,我们便可以将程序编译为可执行文件。具体而言,一般需要经历以下过程。

- 预处理阶段。预处理器(cpp)根据 # 开头的命令修改原始的C程序。在这里,include语句告诉预处理器将stdio.h文件中从内容插入程序文本中。经过这一步,我们实现了从 hello.c到hello.i的变化。
- 编译阶段。编译器(ccl)将文本文件 hello.i 翻译成 hello.s ,即翻译为汇编语言程序。
- 汇编阶段。汇编器(as)将 hello.s 翻译为机器语言指令并打包为可重定位目标程序的格式,并保存在二进制文件 hello.o 中。
- 链接阶段。在hello程序中调用了printf函数,该函数保存在printf.o文件中,链接过程就是将这些文件以某种方式进行合并。合并完成后我们得到可执行目标文件 hello。
在得到可执行目标文件后,我们可以将其输入到shell(命令行解释器)中。
为了更深入的理解运行程序时计算机内部发生了什么,我们需要了解一个典型系统的硬件知识。
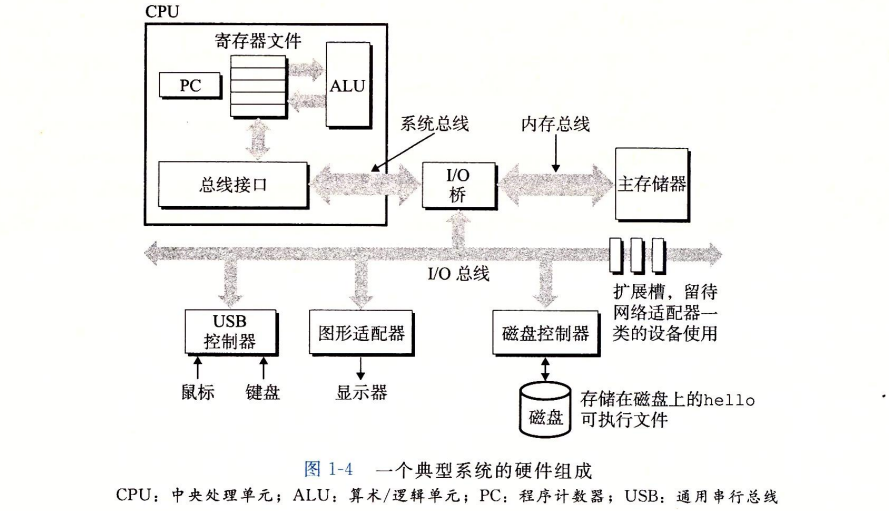
总线
总线携带信息字节并负责在各个部件之间进行传递。通常总线被设计为定长的字节块,也就是字(word)。32位指代4字节,而64位指代8字节。
I/O设备
输入输出设备时系统与外部世界进行联系的通道。常见的I/O设备包括键鼠、显示器、磁盘等。每个设备都通过一个控制器或适配器与I/O总线相连。
控制器与适配器之间的区别在于封装方式。控制器通常是I/O设备本身或者系统的主板上的芯片组,而适配器时插在主板上的卡。
主存
主存是一个临时存储设备,用于存放程序和程序处理的数据。主存由一组动态随机存取存储器(DRAM)芯片组成。从逻辑上来说,存储器是一个线性的字节数组,每一个字节都有其唯一的地址(数组索引)。
处理器
处理器(CPU)是解释(或执行)存储在主存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(或寄存器),称为程序计数器(PC),在任何时刻,PC都指向主存中某条机器指令。
指令集架构决定指令执行模型。
在运行代码的过程中,数据需要在内存、处理器、总线上来回搬运。因此要提高运行速度,就需要是这些复制搬运操作加快。我们可以通过在处理器和较大较慢的设备(例如主存)之间插入一个更小更快的存储设备(例如cache)来加速这个过程,于是便产生了一个存储器层次结构。
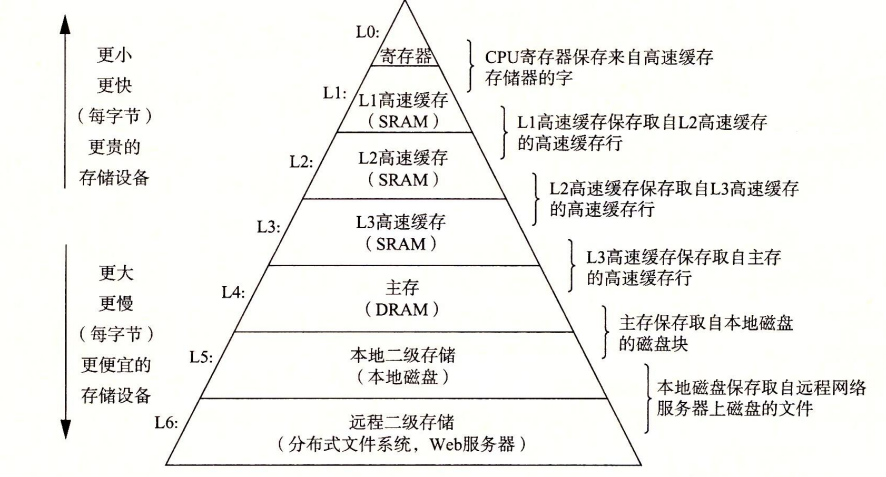
为了防止硬件被失控的应用程序滥用以及提供一个简单一致的机制来控制复杂低级的硬件,我们使用操作系统来提供这些服务。操作系统提供了几个基本的抽象概念来实现基本功能。
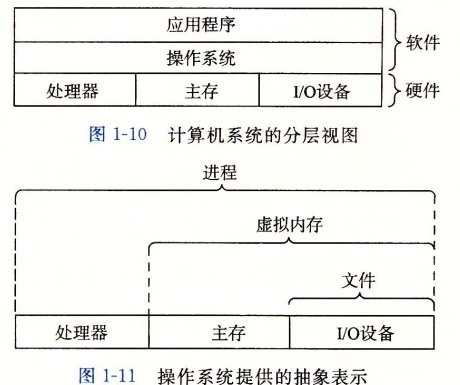
进程
进程是操作系统对正在运行的程序的一种抽象。一个系统可以同时运行多个进程。在系统中,一个CPU通过在进程之间切换来实现交错执行的机制,称为上下文切换,也是CPU能进行并发执行的原因。在这里,上下文是一个抽象的概念,指操作系统保持跟踪进程运行所需的所有状态信息。上下文切换时,操作系统会保存当前状态的上下文,恢复新进程的上下文。新进程会从上次中断的地方开始。
线程
一个进程可以由多个称为线程的执行单元组成。
虚拟内存
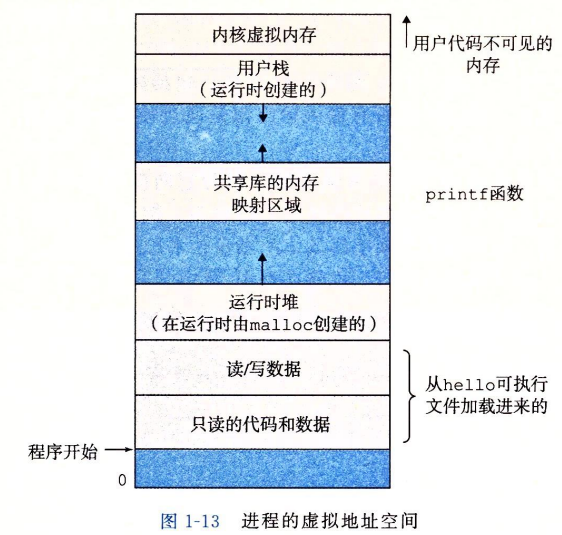
虚拟内存为每一个进程提供了一个假象,即每个进程都在独占地使用主存。每个进程看到的内存是一致的,称为虚拟地址空间。
对于所有进程而言,代码是从统一固定位置开始,紧接着的是和C全局变量相对应的数据位置。
涉及的一些名词和概念:
- 运行时堆:代码和数据在进程一开始时确定大小,调用函数时堆可以在运行时动态的扩展和收缩。
- 共享库:用于存放C标准库和数学库这样的共享的代码和数据。
- 用户栈:用于实现函数的调用。调用函数时会导致栈增长,函数返回时栈收缩。
- 内核虚拟内存:应用程序调用内核执行操作。
Amdahl定律:在对系统某个部分进行加速时,其对系统整体性能的影响取决于该部分的重要性和加速程度。假设执行某应用程序所需要的时间为$T_{old}$,某部分与执行时间总体的比例为$\alpha$,该部分提升性能比例为$k$,则有:
$$
T_{new}=(1-\alpha)T_{old}+(\alpha T_{old})/k=T_{old}[(1-\alpha)+\alpha/k]
$$
$$
S=T_{old}/T_{new}= \frac{1}{(1-\alpha)+\alpha/k}
$$
$$
k\to\infty,\quad S_\infty=\frac{1}{1-\alpha}
$$
最后,我们来了解并发与并行。一般来说,我们重点从三个抽象级层次来理解。
- 线程级并发。简单来说,就是利用一个处理器同时处理多个线程。这其中需要用到超线程技术,具体来说就是CPU内部的寄存器和PC有多个备份,用于储存不同的线程上下文,而共用一份其它的硬件。
- 指令级并行。利用一个处理器同时执行多条指令。
- 单指令、多数据并行。利用特殊的硬件允许一条指令产生多个可以并行执行的操作,简称SIMD并行。
信息的表示和处理
对应原书CS:APP第二章
将信息以位来表示
在现代计算机系统中,我们通常用位(bits):0/1来表示数据。
| C Data Type | Typical 32-bit | Typical 64-bit |
|---|---|---|
| char | 1 | 1 |
| short | 2 | 2 |
| int | 4 | 4 |
| long | 4 | 8 |
| float | 4 | 4 |
| double | 8 | 8 |
| pointer | 4 | 8 |
布尔代数
布尔代数:我们用0代表false,1代表true
布尔运算:定义四种基本布尔运算。对于 Bit Vectors,采取逐位计算的方式。
- AND: A&B = 1 when A = 1 and B = 1
- OR: A | B = 1 when A = 1 or B = 1 or both
- NOT: ~A = 1 when A = 0
- XOR: A^B = 1 when A != B
对于Bit Vectors 的运算,我们可以采用下面这种表示方式:若一个Bit Vector 定义为A,我们从左至右从0开始给每一位编号,然后将其中为1的位的序号组成一个集合,代表这个向量。
例如:$A=01101001 \quad \rightarrow \quad {0,3,5,6},B=01010101 \quad \rightarrow \quad {0,2,4,6}$
这样表示后,我们可以将布尔代数转化为集合的运算:
- & 交集(intersection):A&B={0,6}
- | 并集(union):A|B={0,2,3,4,5,6}
- ^ 相异的元素(Symmetric difference):A^B={2,3,4,5}
- ~ 补集(Complement):~A={1,2,4,7}
C语言的Shift Operations:
x<<y:将一个整数x的二进制形式向左移动y位,右侧用0填补,在数学意义上会导致值乘2的y次方。
例:5(0000 0101)<<2 = 5*2^2=20(0001 0100)
x>>y:分为算术右移和逻辑右移。
算术右移会保留符号位(最高位),即右移操作不改变数字的正负。而逻辑右移不考虑符号位,直接将左侧用0填充。
整型
一些关于转换编码的名词:
| 符号 | 类型 | 含义 |
|---|---|---|
| $B$ | 数据类型 | Binary,二进制数 |
| $T$ | 数据类型 | Two’s Complement,补码 |
| $U$ | 数据类型 | Unsigned,无符号数 |
| $\omega$ | 常数 | 数据表示的位数 |
| $X2Y_\omega$ | 函数 | 从$X$的数据类型转换为$Y$ |
| $TMin_\omega$ / $TMax_\omega$ | 常数 | 最小/最大补码值 |
| $UMax_\omega$ | 常数 | 最大无符号数 |
| $+^{t}_{\omega}$ / $+^u_\omega$ | 运算操作 | 补码 / 无符号数加法 |
| $*^t_\omega$ / $*^u_\omega$ | 运算操作 | 补码 / 无符号数乘法 |
| $-^t_\omega$ / $-^u_\omega$ | 运算操作 | 补码 / 无符号数取反 |
无符号数的编码定义:
$$
B2U_\omega(x)=\sum_{i=0}^{\omega-1}x_i 2^i
$$
补码编码定义:即最高有效位的权值为负数。
$$
B2T_\omega(x)=-x_{\omega-1}2^{\omega-1}+\sum_{i=1}^{\omega-2}x_i 2^i
$$
可以把反码理解为最高有效位的权值为$2^{\omega-1}-1$。故有补码=反码+1.
无符号数加法(包含溢出情况):
$$
x+y=\begin{cases}x+y \ ,\ x+y\le2^\omega \\ x+y-2^\omega \ , \ x+y\ge2^\omega \end{cases}
$$
补码加法(包含正溢出和负溢出):
$$
x+y=\begin{cases}x+y-2^\omega \ , \ x+y\ge2^{\omega-1} \\ x+y \\ x+y+2^\omega \ , \ x+y<-2^{\omega-1} \end{cases}
$$
浮点数
浮点数的编码表示:利用小数点后的第$i$位来表示权值为$2^{-i}$的位。
例如,浮点数$0.111_2=1\times2^{-1}+1\times2^{-2}+1\times2^{-3}=0.5+0.25+0.125=0.875$
IEEE浮点表示:IEEE浮点标准用$V=(-1)^s\times M\times 2^E$的形式来表示一个数。
- 符号(sign):s决定这个数的正负属性
- 尾数(significand)M是一个二进制小数,范围是$1\sim 2-\varepsilon$,或者是$0 \sim 1-\varepsilon$
- 阶码(exponent)E的作用是对浮点数进行加权,这个权重是2的E次幂(可能是负次幂)
- 一个单独的符号位编码s
- k位的阶码字段 $exp=e_{k-1}…e_1e_0$编码阶码E
- n位的小数字段$frac=f_{n-1}…f_1f_0$编码位数M
单精度与双精度浮点数的存储:

根据不同的exp的取值,被编码的值可以分为三种不同的情况:
规格化的,此时 $exp \ne 0 且\ne 255$,此时$E=e-Bias$,其中$Bias=2^{k-1}-1$,单精度为127,双精度为1023. 指数的范围为单精度$-126 \sim 127 $,双精度为$-1022 \sim 1023$。
小数字段frac被解释为$0.f_{n-1}…f_1f_0$,尾数定义为$M=1+f$。这种方式也被称为隐含的以1开头的表示。
非规格化,此时$exp=0$,在这种情况下,阶码值是$E=1-Bias$,尾数的值为$M=f$,也就是小数字段的值,不包含隐含的开头的1.
特殊值,当阶码全为1即$exp=255$时,小数域全为0时,得到的值表示无穷。当小数域的结果非0时,结果值被称为NaN。
浮点数的舍入(Rounding):
浮点数的舍入有多种方式,下面举例说明四种常见的舍入方式:
| 方式 | 1.40 | 1.60 | 1.50 | 2.50 | -1.50 |
|---|---|---|---|---|---|
| 向偶数舍入 | 1 | 2 | 2 | 2 | -2 |
| 向零舍入 | 1 | 1 | 1 | 2 | -1 |
| 向上舍入 | 2 | 2 | 2 | 3 | -1 |
| 向下舍入 | 1 | 1 | 1 | 2 | -2 |
向偶数舍入是计算机默认的舍入方式,其原理是找到一个最接近的整数进行舍入,在出现两个结果的中间数时(1.5,2.5等)使舍入后的数最低有效位为偶数。
向偶数舍入的优势是:在计算平均值是,向上舍入或向下舍入会导致整体的平均值偏大或偏小,而向偶数舍入在大多数情况下避免了这种现实偏差,即有50%的概率向上舍入,同时有50%的概率向下舍入。
浮点数的运算:
我们将浮点值的计算定义为$x+y=Round(x+y)$,只需要计算到一个可以得到正确舍入结果的答案即可。
浮点加法不具有结合性。例如$3.14+1e10-1e10=0$,这是因为计算前两项时由于舍入的原因值3.14会丢失。而计算$3.14+(1e10-1e10)=3.14$。
同时,这也导致了浮点乘法不具备分配性。
程序的机器级表示
对应原书第三章内容
程序编码
首先了解几个常见名词:
Architecture(架构):指指令集架构(ISA),是处理器设计的一部分,编写汇编/机器代码的人需要了解这部分。
例子:指令集规范,寄存器
Microarchitecture(微架构):指架构的具体实现方式。
例子:缓存大小和核心频率。
Code Forms(代码形式):分为Machine Code(机器代码)和Assembly Code(汇编代码)。前者主要指处理器执行的字节级程序,后者主要指机器代码的文本表示形式。
ISAs(指令集架构):x86-64,ARM,RISC V等。
下面通过一个例子来了解编程语言、汇编语言和机器码之间的转换:
1 | |
将这段代码转换成汇编代码gcc -Og -S mstore.c,得到的结果如下(省略以“.”开头的行代表的伪指令):
1 | |
而再次将这段代码转为机器码gcc -Og -c mstore.c:
1 | |
利用反汇编器进行反汇编后objdump -d mstore.o:
1 | |
因此,机器执行的程序只是一个字节序列。利用反汇编器,我们可以得到原始的汇编代码。从这个例子中,我们可以总结出这样的规律:
- x86-64的指令长度从1到15个字节不等,常用的指令以及操作数较少的指令所需的字节数烧,而那些不太常用的或操作数较多的指令所需字节数较多。
- 字节可以唯一地解码成机器指令。
- 反汇编器只是基于机器代码文件中的字节序列来确定汇编代码。他不需要访问该程序的源代码或汇编代码。
数据格式
Intel用术语“word”表示16为数据类型,因此称32位数为“double words”,64位数为“quad words”
C语言类型数据在x86-64中的大小,在64为机器中,指针长8字节:
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
一个x86-64的中央处理单元(CPU)包含一个一组16个储存64位值的通用目的寄存器。这些寄存器用来存储正数数据和指针。他们的名字都以%r开头。
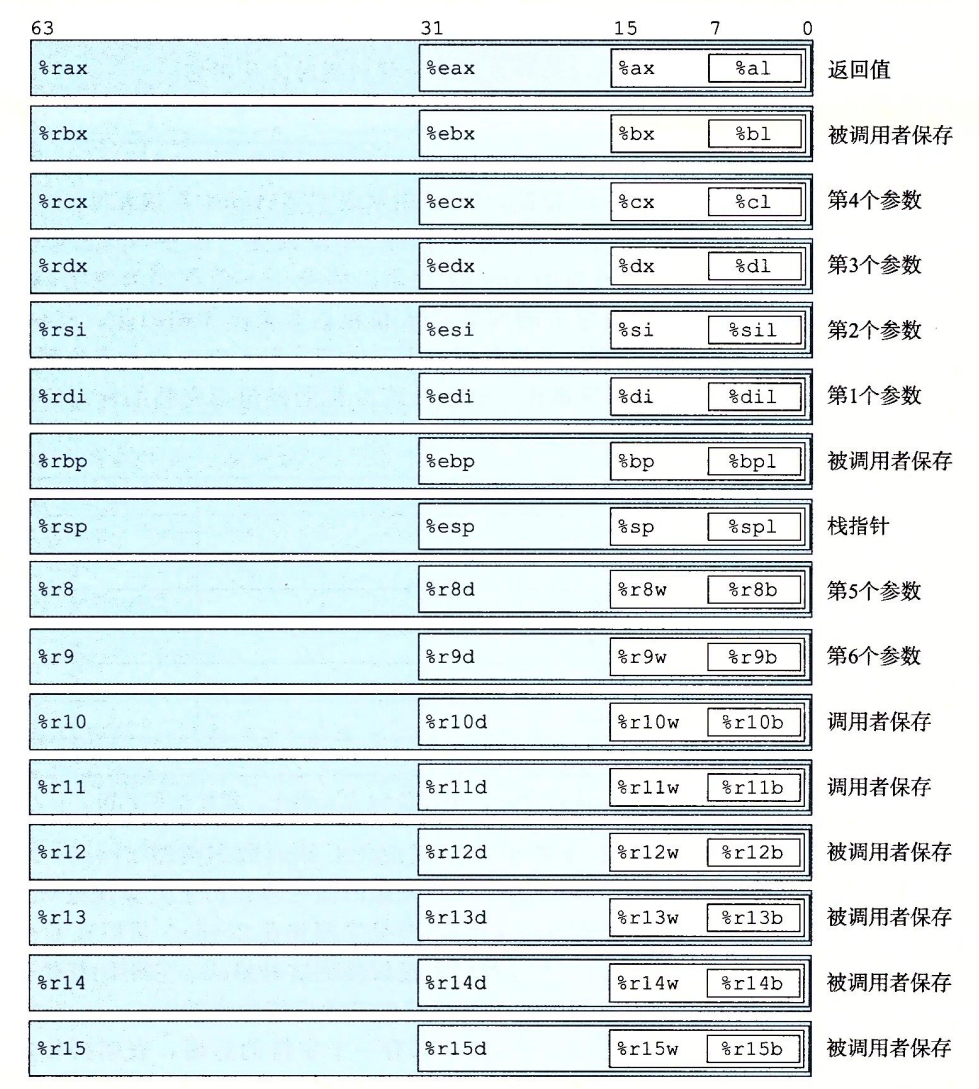
汇编基本指令
基本操作数
各种操作数可以分为三种类型:
立即数,用于表示常数值,书写方式为”$”后跟一个用C表示法表示的整数。
寄存器,表示某个寄存器的内容,16个寄存器的低位1、2、4、8字节中的一个作为操作数,对应8、16、32、64位。我们用$r_a$表示寄存器a,用$R[r_a]$来表示它的值。这表示将寄存器集合看成一个数组。
寄存器有一个特点:任何为寄存器生成32位值的指令都会把该寄存器的高位部分置为0.
内存引用,根据据计算出来的有效地址访问某个内存位置。因为将内存看成一个很打动字节数组,我们用符号$M_b[Addr]$表述对存储在内存中从地址Addr开始的b个字节的引用。
一种最常见的寻址模式:$Imm(r_b,r_i,s)$,包括四个组成部分,一个立即数偏移$Imm$,一个基址寄存器$r_b$,一个变址寄存器$r_i$,一个比例因子$s=1,2,4,8$,有效地址的计算为$Imm+R[r_b]+R[r_i]\cdot s$
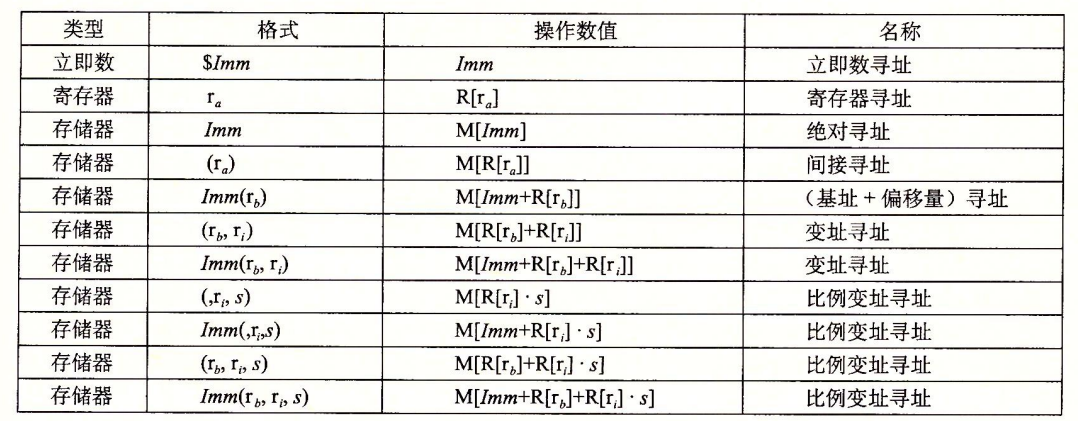
数据复制
数据传送指令——MOV类。这些指令把数据从源位置复制到目的位置,不做任何变化。
MOV类指令由四条指令组成:movb,movw,movl,movq。这些指令操作的数据大小分别为1、2、4、8字节。源操作数指定的值是一个立即数,储存在寄存器中或者内存中。目的操作数指定一个位置,要么是一个寄存器或者是一个内存地址。
源和目的的组合有五种:I2R,I2M,R2R,R2M,M2R。
I–Imm R–register M–Memory
常规的movq指令只能以表示为32位补码数字的立即数作为源操作数,然后把这个值符号拓展得到64位的值,放到目的位置。而movabsq指令能够以任意64位立即数值位源操作数,并且只能以寄存器作为目的。
基于MOV类衍生出MOVZ类和MOVS类指令,用于将较小的源值复制到较大的目的时使用。所有这些指令的目的都为寄存器。MOVZ使用零扩展,而MOVS使用符号扩展。MOVS类中的cltq只用于将%eax符号扩展到%rax,效果与movslq %eax,%rax完全一致,不过编码更紧凑。
关于直接寻址和间接寻址:在学习时,笔者对直接寻址和间接寻址的概念比较模糊,在这里对于这两个概念进行总结,以一个例子入手。
1 | |
这里有两个关键易混淆的点要注意:
- 在指令中,
value并不是一个立即数,而是看做内存中的一个地址(假设为0x1000),在内存0x1000这个地址储存了整数10。因此,第一步操作mov value, %rbx代表将地址0x1000存入rbx寄存器中而不是将数值10存入rbx。 - 第二步很好地说明了间接取址和直接取址之间的区别:
(%rbx)代表的是内存中的一个地址,具体为rbx内储存的地址0x1000。而%rcx代表寄存器中的rcx。这步操作将rbx寄存器指向的内存地址0x1000处的值(即value的值,这里是 10)移动到rcx寄存器中。这里可以把内存和寄存器看为两个不同的数组M和R,rbx存放的是0x1000=R[r_b],rcx存放的是数10=R[r_c],(%rbx)=M[R[r_b]]=M[0x1000]存放的是value的值。
压栈/弹栈
栈是满足先入后出的顺序结构,一般用push代表压栈,pop代表出栈。栈指针%rsp保存着栈顶元素的地址。
| 指令 | 效果 | 描述 |
|---|---|---|
| pushq S | R[%rsp]-8 $\to$ R[%rsp];S $\to$ M[R[%rsp]] | 将四字压入栈 |
| popq D | M[R[%rsp]] $\to$ D;R[%rsp]+8 $\to$ R[%rsp] | 将四字弹出栈 |
指令 pushq %rbp的行为等价于:
1 | |
同理,指令popq %rax等价于:
1 | |
算术和逻辑操作
操作被分为四类:加载有效地址,一元操作,二元操作和移位。
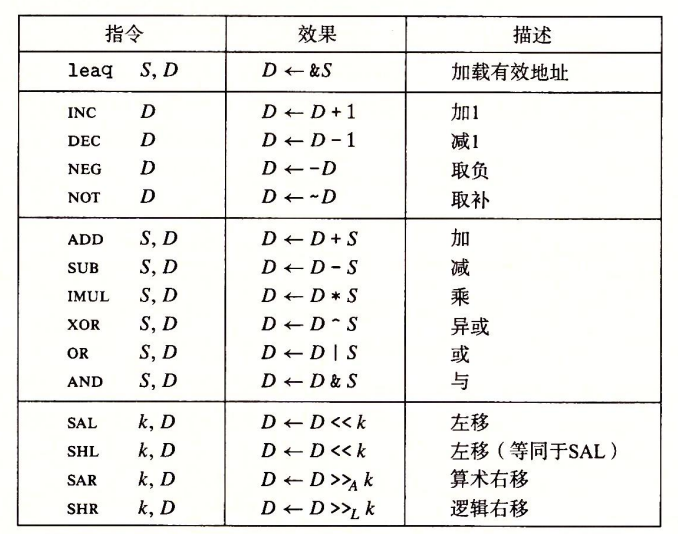
加载有效地址(load effective address)指令实际上是
movq指令的变形。在形式上是从内存读取数据到寄存器,但实际上根本没有引用内存。第一个操作数看上去是一个内存引用,但实际上是将有效地址写入到目的操作数。例如:
leaq 7(%rdx, %rdx, 4), %rax。我们假设rdx的值为$x$,那么rax的值为$5x+7$.所以,利用这条指令,我们可以实现简单的算术运算。
一元操作:具体涉及到四种操作,分别是加一、减一、取负、取补
二元操作:前面的操作数称为源S,第二个操作数称为目的D,结果被存储在目的D里面。
移位操作:注意逻辑右移和算数右移的区别,逻辑左移和算术左移没有区别。
除开上面讨论的几种操作之外,还有几类特殊的算术操作。两个64为有符号数或无符号数相乘需要128位来表示。在x86-64指令集中,对128位(16bytes)的操作提供一些有限的支持。这些特殊操作就是对16字进行操作。
| 指令 | 效果 | 描述 |
|---|---|---|
| imulq/mulq S | R[%rdx];S*R[%rax] –> R[%rax] | 有符号/无符号全乘法 |
| clto S | 转换为8字 | |
| idivq/divq S | 有符号/无符号除法 |
在执行两个64位数的128位乘积是,要求一个参数必须在寄存器%rax中,另一个作为指令的源操作数给出,然后将乘积存放在%rdx(高64位)和%rax(低64位)中。
下面从C语言和汇编代码的角度进一步剖析这条指令:
1 | |
gcc生成的汇编代码如下:
1 | |
对于大多数64位除法应用来说,除数也常常是一个64位的值,这个值应该存放在%rax中,%rdx的位应该全设置为0或者符号位。后面这个操作可以用指令cqto来完成,它不需要操作数,会隐含读出%rax的符号位并复制到%rdx的所有位。
从C语言和汇编代码的角度进行进一步解析:
1 | |
gcc生成的汇编代码:
1 | |
条件码
除了整数寄存器,CPU还维护了一组单个位的条件码寄存器,描述了最近的算数或逻辑操作的属性,可以检测这些寄存器来执行条件分支指令。最常用的条件码包括:
- CF:进位标志。最近的操作数是最高位产生了进位,可以检测无符号操作的溢出。
- ZF:零标志。最近的操作得到的结果为0.
- SF:符号标志。最近的操作得到的结果为负数。
- OF:溢出标志。最近的操作导致一个补码溢出。
leaq操作不改变任何条件码,除此之外其余指令都有可能改变条件码。对于逻辑操作,进位和溢出标志会被设为0.
我们也可以使用一些指令来设置条件码:
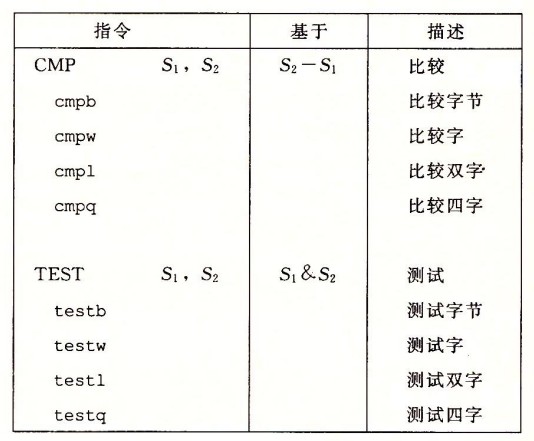
其中,CMP指令根据两个操作数之差来设置条件码,TEST根据两个操作数的AND运算。典型用法是将两个操作数设置为一样的来检测正负,或者将一个设置为掩码来测试特定位。
条件码一般有三种使用方式:
- 根据条件码的某些组合,将一个字节设置为0或者1
- 条件跳转到程序的某个部分
- 有条件地传输数据
实现条件码设置字节我们使用SET指令,在指令中,“设置”代表赋值为1。
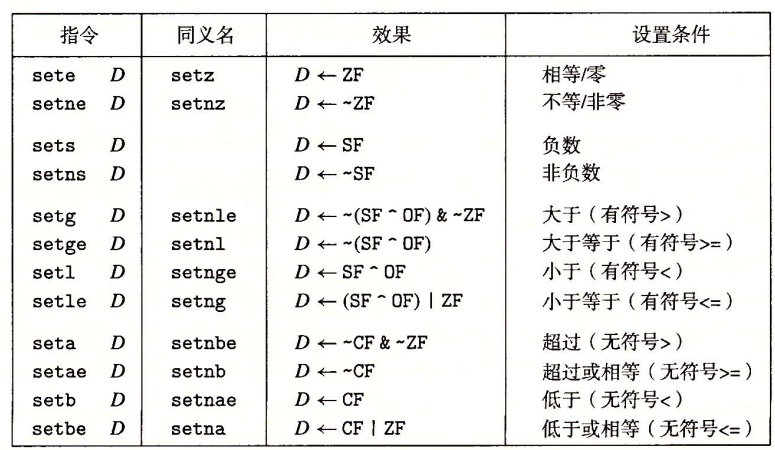
分析各函数的效果,我们发现有符号数的比较主要涉及SF,OF,ZF,而无符号数的比较涉及CF,ZF。
下面是一个例子,实现比较两个数:
1 | |
此处主要注意movzbl指令(1 to 4),该指令不仅会把%eax的高3个字节清零,还会把整个寄存器%rax的高四个字节都清零。
我们假设此处a<b,那么cmpq会将SF、CF置为1,而ZF、OF为0 。接下来setl指令会将SF^OF的值赋给D,因此在这里%al将被设置为1,最终函数返回结果为1.
跳转指令
jump指令会导致执行切换到程序中一个全新的位置。在程序中,一般会有一个Label来指明跳转的位置。
跳转指令可以是直接跳转,即跳转目标是作为指令的一部分来编码的;也可以是间接跳转,即跳转目标是从寄存器或内存位置中读出的。直接跳转直接使用一个标号作为跳转目标,而间接跳转的写法是*+操作数指示符。
例如指令jmp *%rax用寄存器%rax中的值作为跳转目标,而指令jmp *(%rax)用%rax中的值读出地址,从内存中读出跳转目标。
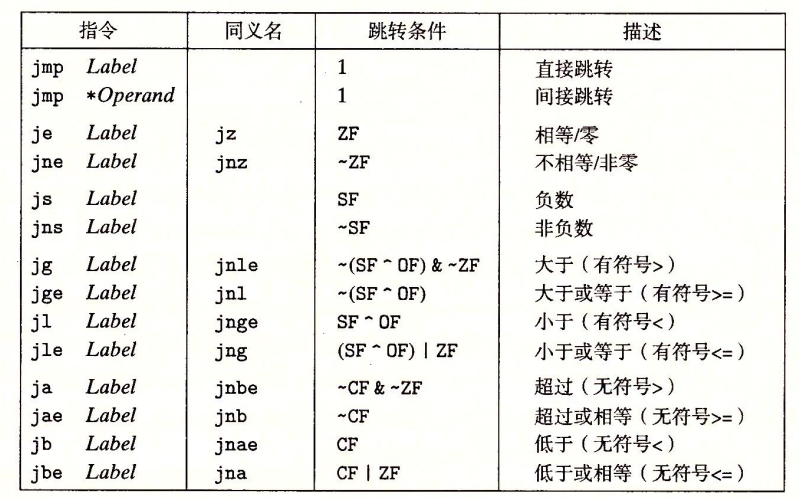
跳转指令的编码:在汇编代码中,跳转目标用符号标号书写。跳转指令有几种不同的编码,但常用的都是PC相对的。也就是会将目标指令的地址紧跟在跳转指令后面的那条指令的地址间的差值作为编码,可以是1、2、4字节。第二种方法是绝对地址编码,用四个 字节直接指定目标。
下面看一个例子:
1 | |
对应的反汇编版本:
1 | |
这里可以从反汇编器产生的注释明确读出.L2的跳转目标指明为0x8(test行),.L3为0x5 (sar行)。而观察字节编码,发现.L2的字节编码为03,而.L3的字节编码为f8 。这里就是利用PC相对的编码方式,目标指令(test行)为0x8,下一条指令(sar行)地址为0x5,故差值0x3为.L2编码。同理,目标指令(sar行)为0x5,下一条指令(rep行)为0xd,插指0xf8(十进制-8)为.L3编码。
因此,三个地址之间我们可以做到知二求一。目标地址=标志编码+下一行地址
利用跳转指令,我们可以实现条件分支和循环结构。
条件分支
下面是一个用控制的条件转移思路写出的代码。
1 | |
与上述代码等价的goto代码:
1 | |
将goto代码转换为汇编代码:
1 | |
当然,有时为了提高效率,我们可以使用数据的条件转移,即先计算出所有分支产生的结果,再判断需要传送哪个结果。例如下面这个例子:
1 | |
产生的汇编代码:
1 | |
里面涉及到一类条件传送指令:comv,条件传送指令再条件满足时把源值S复制到目的R。

当然,需要注意的是,不是所有条件表达式都可用条件传送来编译。最重要的是,当语句会产生除返回值的副作用时,可能会导致一些错误。
循环结构
do-while循环
该语句的通用形式如下:
1
2
3do
body-statement
while(test-expr)这种通用形式可以被翻译为如下所示的条件和goto语句:
1
2
3
4
5loop:
body-statement
t = test-expr;
if(t)
goto loop;假设我们有一个实现阶乘的函数,下面是一个等价的汇编代码:
1
2
3
4
5
6
7
8
9;n in %rdi
fact_do:
movl $1, %eax ;Set result = 1
.L2: ;Loop:
imulq %rdi, %rax ; result *= n
subq $1, %rdi ; n = n-1
cmpq $1, %rdi ;Compare n:1
jg .L2 ;if >, goto Loop
rep; ret ;Returnwhile循环
通用形式如下:
1
2while(test-expr)
body-statement与上一个循环的不同之处在于,我们需要在第一次运行代码之前进行条件判断。
1
2
3
4
5
6
7goto test;
loop:
body-statement
test:
t = test-expr;
if(t)
goto loop;另一种方式是将while转换为do-while:
1
2
3
4
5
6
7t = test-expr;
if(!t)
goto done;
do
body-statement
while(test-expr);
done:for循环
for循环的通用形式如下:
1
2for(init-expr; test-expr; update-expr)
body-statement可以利用while循环改写:
1
2
3
4
5init-expr;
while(test-expr) {
body-statement
update-expr;
}switch语句
在这里,我们引入一个新的数据结构跳转表,跳转表是一个数组,每个元素是一个指向代码位置的指针,:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19void switch_eg_impl(long x, long n, long *dest)
{
// Table of code pointers
static void *jt[3]={&&loc_A, &&loc_B, &&loc_C}
unsigned long index = n - 100;
long val;
if(index>6)
goto loc_def;
goto *jt[index];
loc_A:
val = x*13;
goto done;
loc_B:
x = x + 10
......
done:
*dest = val;
}在C语言中,switch语句依靠跳转表实现。而在汇编代码中,跳转表以如下声明来表示:
1
2
3
4
5
6.section .rodata
.align 8
.L4:
.quad .L3 ;Case 1
.quad .L8 ;Case 2
.quad .L5 ;Case 3
过程
过程提供了一种代码的封装方式,用一组指定的参数和一个可选的返回值实现了某种功能。然后可以在程序中不同的地方调用这个函数。不同编程语言中,对过程的定义多种多样:函数(function),方法(method),子例程(subroutine),处理函数(handler)等,但是它们有一些共有的特性。
假设过程P调用过程Q,Q执行后返回到P。这些动作包括下面一个或多个机制:
- 传递控制,在进入过程Q的时候,程序计数器必须被设置为Q的代码的起始地址,然后在返回时,要把程序计数器设置为P中调用Q后面那条指令的地址。
- 传递数据,P必须能够向Q提供一个或多个参数,Q必须能够向P返回一个值。
- 分配和释放内存,在开始时,Q可能需要为局部变量分配空间,而在返回前,又必须释放这些存储空间。
接下来,我们先描述控制,再描述传递,最后描述内存管理。
运行时栈
在x86-64中,运行时栈向低地址方向增长。当过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间。这个过程称为过程的栈帧。下图给出了一个运行时栈的通用结构:
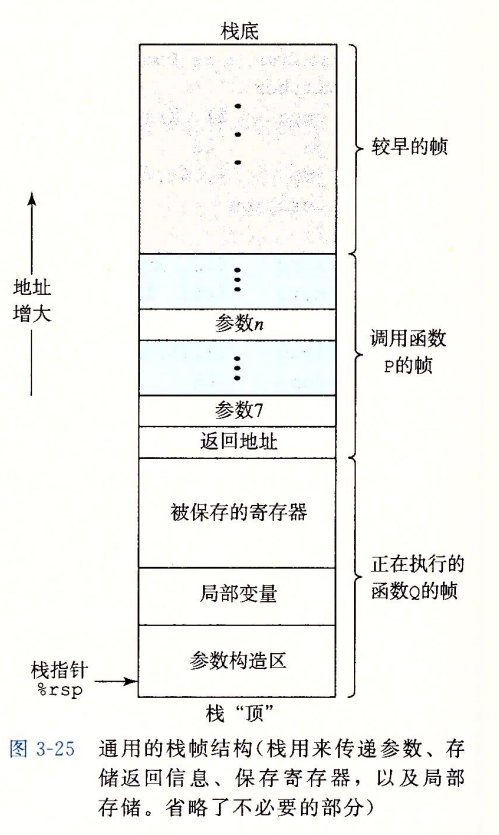
当前正在执行的过程的帧总是在栈顶。当过程P调用Q时,会将返回地址压入栈中,指明当Q返回时,要从P程序的哪个位置继续执行。我们把这个返回地址当作P栈帧的一部分。Q的代码会扩展当前栈的边界,分配它的栈帧所需的空间。借助寄存器,过程P最多可以传递6参数。也就是说,当参数不多于6个时,可以不创建栈帧。
控制转移
将控制从函数P转到函数Q只需要简单把PC设置为Q的代码的起始位置。不过Q返回时,处理器必须记录好它需要继续P的执行的代码位置。在x86-64机器中,这个信息是用指令call来记录的。该指令会将地址A压入栈中,并将PC设置为Q的起始地址。压入的地址A被称为返回地址,是紧跟在call指令后面那一条指令的地址。ret会将A弹出并把PC设置为A。
利用下图我们可以更加直观的感受到call函数的运行:
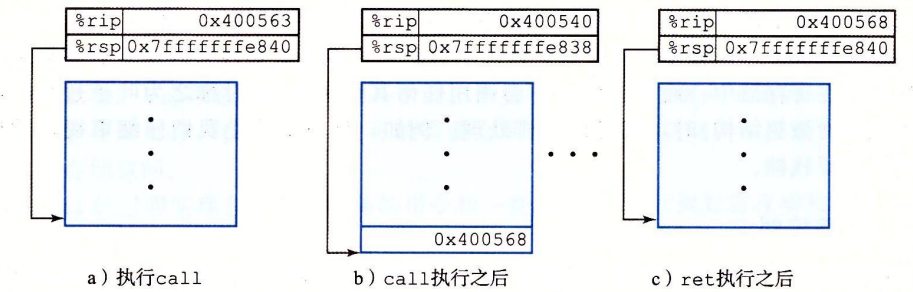
数据传送
当调用一个过程时,除了要把控制传递给它并在过程返回时再传递回来之外,过程调用还可能包括把数据作为参数传递,而从过程返回还有可能包括返回一个值。
x86-64中,可以通过寄存器传递最多6个整型参数。寄存器的使用是有特殊顺序的,寄存器使用的名字取决于要传递的数据类型的大小,如下表所示:
| 操作数大小(位)/参数数量 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 64 | %rdi | %rsi | %rdx | %rcx | %r8 | %r9 |
| 32 | %edi | %esi | %edx | %ecx | %r8d | %r9d |
| 16 | %di | %si | %dx | %cx | %r8w | %r9w |
| 8 | %dil | %sil | %dl | %cl | %r8b | %r9b |
如果一个函数有大于6个的参数,那么超出6个的部分需要通过栈来传递。
下面看一个例子:
1 | |
生成的汇编代码:
1 | |
寄存器组是唯一被所有过程共享的资源,虽然在给定时刻只有一个过程是活动的,但是仍然需要保证一个过程在调用时不会覆盖另一个过程保存的数据。
按照惯例,寄存器%rbx,%rbp以及%r12-%r15被划分为被调用者保存寄存器,举个例子就是在P调用Q时,Q必须保存这些寄存器的值不能改变。
同样的,由于栈的特点,我们可以很容易理解递归函数的调用过程。
数组
对于数据类型T和整型常数N,我们声明一个数组如下:T A[ N ];
这个声明有两个效果:首先在内存中分配一个L*N字节的连续区域,这里的L是指数据类型T的大小。其次引入了一个标识符A,作为指向数组开头的指针。
假设我们访问一个int数组,E的地址存放在%rdx中,i存放在%rcx中,那么访问E[i]的指令为:movl (%rdx,%rcx,4), %eax。
C语言允许对指针进行运算,其效果为将指针指向下一个数据类型大小的地址。例如*(E+1)的效果等同于E[1]。下表给出了一些常见的指针运算:

这里需要注意,两个指针相减计算的是指针之间的距离,以元素为单位。
同样的,嵌套数组在储存中也是线性储存的,即按照行优先的顺序排列。
结构体和联合
结构体的所有组成成分都存放在内存中一段连续的区域内,而指向结构的指针就是结构第一个字节的地址。编译器指示每个字段的字节偏移,以这些偏移作为内存引用指令中的唯一,从而产生对结构元素的引用。
下图的例子可以很好的说明:

而共用体用于将不同类型的数据存储在同一块内存空间中。所有成员共享相同的内存位置。
内存分配:共用体的大小是其最大成员的大小,所有成员重叠存储在同一内存空间中。
访问:同一时间只能访问一个成员,修改一个成员会影响其他成员的值。可以简单理解为Union可以作为代表它内部的任何一个成员的单个元素,而结构体是包含内部成员的集合。
考虑:
1 | |
可以同时访问S3中的c,i和v,因为在结构体中这三者是同时存在的的。而U3可以作为其中之一出现,三者不是同时存在的。
字段偏移量如下:
| 类型 | c | i | v | 大小 |
|---|---|---|---|---|
| S3 | 0 | 4 | 16 | 24 |
| U3 | 0 | 0 | 0 | 8 |
这里涉及到数据对齐的原则,即某种类型对象的地址必须是某个值K(通常是2,4,8)的倍数。因此在这里尽管char c只占用了一个字节,但是i的起始地址仍然是4.同时i结束后v起始地址应该是12,但为了double的数据对齐,起始地址必须为8的倍数,因此起始地址为16.
指针
指针是C语言的一个核心特色,他们以一种统一的方式,对不同的数据结构中的元素产生引用。下面重点介绍一些指针和它们映射到机器代码的关键原则:
每个指针都对应一种数据类型。
特殊指针
void *类型代表通用指针,可以通过强制类型转换或者赋值操作那样的隐式强制类型转换将其转换成一个有类型的指针。注意指针类型不是机器代码中的一部分,它们是C语言提供的一种抽象,帮助理解避免寻址错误。每个指针都有一个值。这个值是某个指定类型对象的地址。
指针用‘&’运算符创建。&运算符的机器代码实现常常利用指令
leaq。‘*’操作符用于简介引用指针。其结果是一个值,类型与指针类型一致。
将指针从一种类型强制转换为另一种类型,不改变指针的值。
指针可以指向函数。例如:
1
2
3
4
5int fun(int x, int *p);
int (*fp)(int ,int *);
*fp = fun;
int y = 1;
int result = fp(3, &y);函数指针的值是该函数机器代码表示中第一条指令的值。
浮点代码
AVX浮点体系结构允许数据存储在16个YMM寄存器中,命名为%ymm0 $\sim$ %ymm15,每个YMM寄存器都是256位(32字节)。低16字节命名为%xmm0 $\sim$ %xmm15.
相应的,浮点操作也包括传送、转换、运算、比较等,下面直接给出对应的指令表:
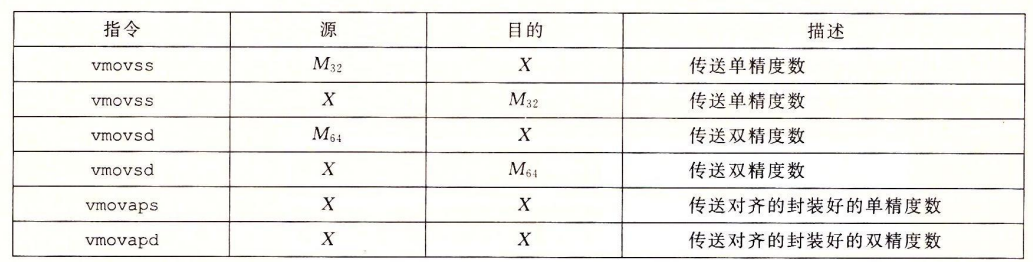
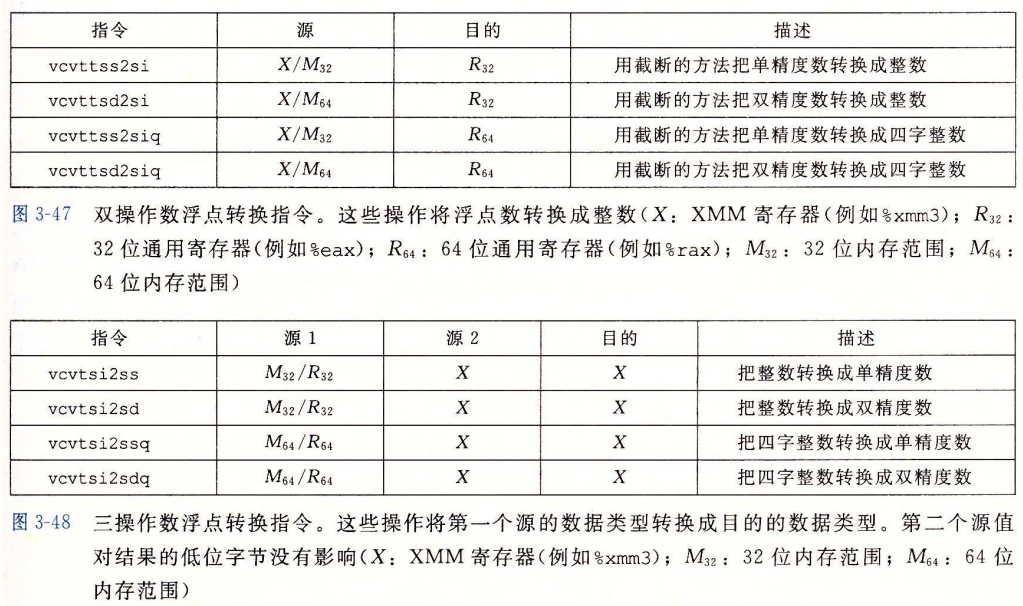
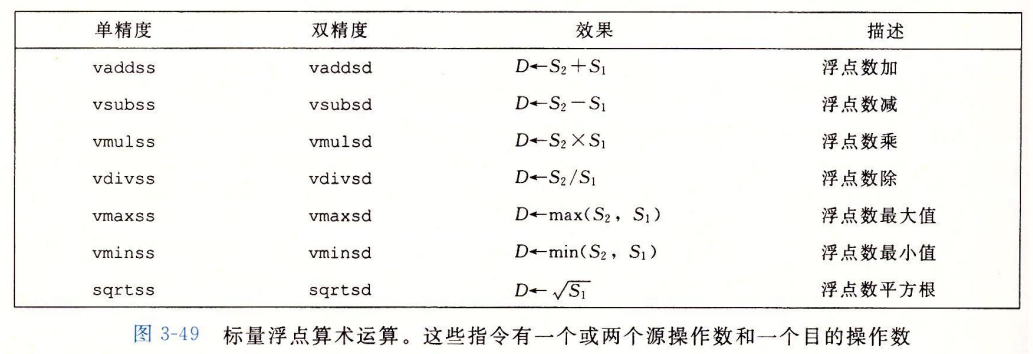
处理器体系结构
对应原书第四章
Y86-64指令集体系结构
定义一个指令集体系结构包括定义各种状态单元、指令集以及它们的编码、编程规范和异常事件处理。
程序员可见的状态
Y86-64 程序章中的每条指令都会读取或修改处理器状态的某些部分,这称为程序员可见状态。
一半而言,程序员可见的状态包括以下几类:
- RF:程序寄存器。在Y86-64中,包含15个程序寄存器,每个存储着一个64位的字。
- CC:条件码,保存着最近的算数或逻辑指令造成的相关影响。
- DMEM:内存,保存着程序和数据。
- PC:程序计数器,存放当前正在执行指令的程序。
- Stat:程序状态,表明程序执行的总体状态。
指令以及指令编码

下面是一些细节:
- movq指令被细分为了四种,前缀ir,rr,mr,rm代表源和目的。
- 整数操作指令只有四个,为addq,subq,andq以及xorq。
- 6个条件传送指令,只有当条件码满足所需要的约束时才会更新目的地的寄存器值。
- halt指令停止指令的执行,将状态码设置为HLT。
对于指令及其分支,我们对其进行编码: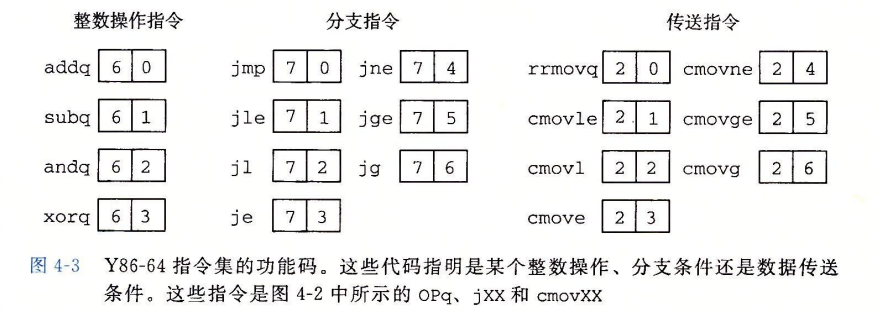
对于寄存器,我们用0x0到0xF来表示,前15个代表寄存器,最后一个代表无寄存器。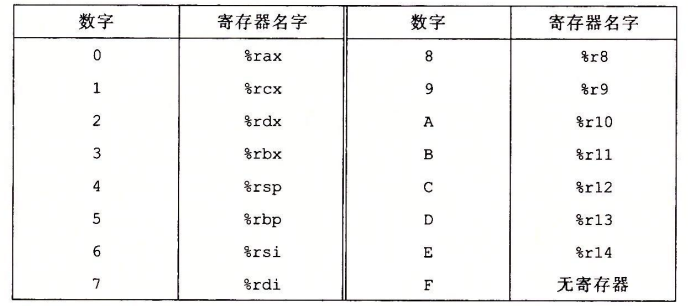
有一些指令需要附加8字节常数字,这个字能够作为irmovq的立即数数据,rmmovq和mrmovq的地址指示符的偏移量,以及分支指令和调用指令的目的地址。
例如,我们用十六进制来表示指令rmmovq %rsp 0x123456789abcd(%rdx)的字节编码。从图中我们可以看出,rmmovq的第一个字节为40,两个寄存器放在rA和rB字段中,这里得到寄存器指示符字节42.最后将偏移量放在八字节常数字中,为:
00 01 23 45 67 89 ab cd
小端法编码需要反序:cd ab 89 67 45 23 01 00
所以整段指令的编码:40 42 cd ab 89 67 45 23 01 00.
异常
在y86-64指令集中,用Stat指示程序的当前状态:
| 值 | 名字 | 含义 |
|---|---|---|
| 1 | AOK | 正常操作 |
| 2 | HLT | 遇到执行hlt指令 |
| 3 | ADR | 遇到非法地址 |
| 4 | INS | 遇到非法指令 |
程序实例
先写一个C函数:
1 | |
对应的Y86-64代码:
1 | |
注意几个细节:
- Y84-64将常数加载到寄存器中,因为在算术指令中不能使用立即数
- 要实现从内存读取一个数据并相加,Y84-64需要两条指令。
Y86-64 的顺序实现
了解了有关Y86-64的一些基本知识后,我们可以实现Y86-64.首先,我们需要一个称为“SEQ”的顺序处理器。
通常,处理一条指令包括很多操作,基本而言可以分为以下几个阶段:
取指(fetch):从内存读取10指令字节,地址位程序计数器PC的值。从指令中抽取出指令指示符字节的两个四位部分,称为icode和ifun,代表指令代码与指令功能。计算下一指令的地址为:
$valp = PC+已取出指令的长度$
译码(decode):从寄存器文件读入最多两个操作数,得到值valA和valB
执行(execute):在执行阶段,ALU要么执行指令指明的操作,计算内存引用的有效地址,要么增加或减少栈指针。得到的值称为valE。也可能设置条件码。
访存(memory):将数据写入内存,或者从内存读取数据。
写回(write back):写回阶段最多将两个结果写回到寄存器。
更新PC(PC update):将PC设置为下一条指令的地址。
下面我们通过将几个基本指令按阶段拆分来观察:


较难的是pishq和popq指令:
| 阶段 | pushq rA | popq rA |
|---|---|---|
| 取指 | icode:ifun$\leftarrow M_1[PC]$ | icode:ifun$\leftarrow M_1[PC]$ |
| rA:rB$\leftarrow M_1[PC+1]$ | rA:rB$\leftarrow M_1[PC+1]$ | |
| valP $\leftarrow$ PC+2 | valP $\leftarrow$ PC+2 | |
| 译码 | valA $\leftarrow$ R[rA] | valA $\leftarrow$ R[%rsp] |
| valB $\leftarrow$ R[%rsp] | valB $\leftarrow$ R[%rsp] | |
| 执行 | valE $\leftarrow$ valB+(-8) | valE $\leftarrow$ valB + 8 |
| 访存 | M[valE]$\leftarrow$ valA | valE $\leftarrow$ M[valA] |
| 写回 | R[%rsp]$\leftarrow$ valE | R[%rsp] $\leftarrow$ valE |
| R[rA] $\leftarrow$ valM | ||
| 更新PC | PC$\leftarrow$ valP | PC$\leftarrow$valP |
SEQ硬件结构
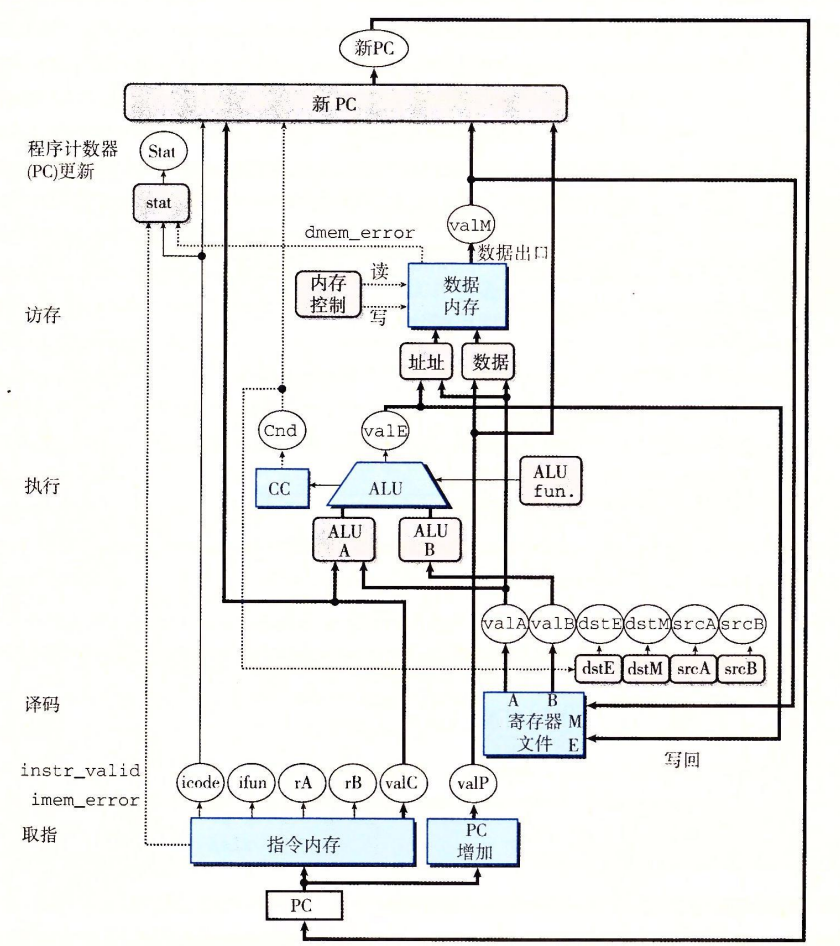
SEQ的实现包括组合逻辑和时钟寄存器、随机访问寄存器。组合逻辑不需要任何时序或控制。
基于上面的硬件结构,我们可以对每个阶段进行具体的实现:
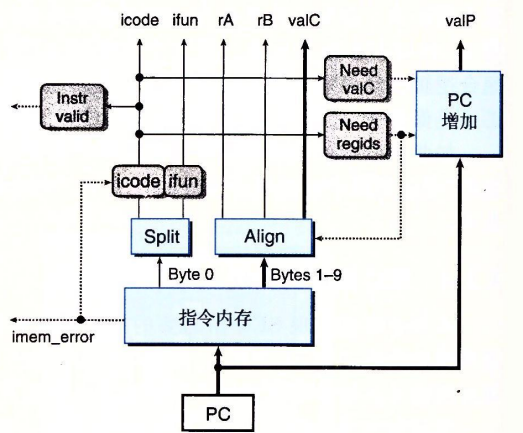
取指阶段。
以PC为起始地址,从内存中读取10个字节,根据这些字节产生各个指令字段。
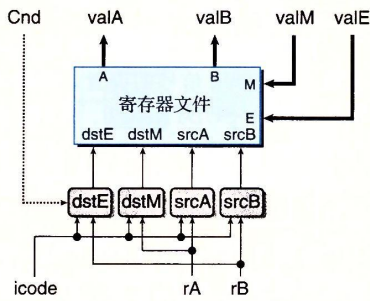
译码和写回。
寄存器文件有四个端口,支持同时进行两个读和两个写操作,每个端口都有一个地址链接和数据连接,地址链接是一个寄存器ID,而数据连接是一条64线路。在这里需要注意的是在读取时 需要读取icode信号,原因是一些指令会涉及到%rsp的读写操作,通过icode信号指示。
执行阶段。
执行阶段ALU对输入aluA和aluB进行ADD,SUB,AND或XOR运算,设置条件码,并将结果储存为valE输出。
标号为cond的硬件单元会根据条件码和功能码来确定是否进行条件分支或条件数据传送,它产生信号Cnd,用于设置条件传送的destE。
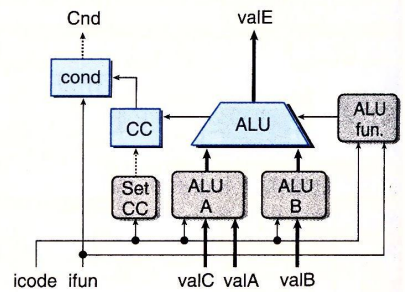
访存阶段。
两个控制块产生内存地址和内存输入数据的值,另外两个块产生应该是读还是写的控制信号。当执行读操作时,内存产生值valM。
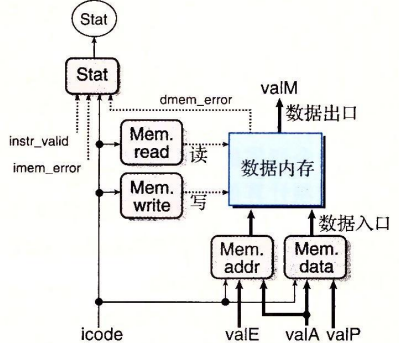
更新PC阶段。
根据指令代码和分支标志,产生新的PC值。
流水线设计
在SEQ设计中,每条指令结束之后,系统再执行下一条指令。但事实上不需要等待指令完全执行之后再开始进行下一指令的执行。
假设我们将一条指令的执行分为三个阶段ABC,那么在指令1执行完A阶段后,指令2便可以开始执行A阶段,同时指令一进入B阶段的执行。以此类推,假设每个阶段的执行时间为120ps,那么每120ps都有一条指令执行完毕,一条新指令开始执行。
一般而言,每个阶段所需的时间是不一致的,这时我们取时间最长的为时钟周期。
了解流水线设计的原理之后,我们尝试设计一个流水线化的Y86-64处理器。首先我们来对现有的SEQ处理器做一些小的改动,将PC的计算挪到取指阶段,之后在各个阶段之间加上流水线寄存器。
SEQ+作为实现流水线化设计的一个过渡阶段,我们必须稍微调整一下SEQ中五个阶段的顺序,使更新PC阶段在一个时钟周期开始时执行而不是结束时执行。
因此,我们需要保存上一个时钟周期内计算出来的信号值,在下一个周期开始时计算出新PC值。
基于SEQ+,我们在各个阶段之间插入流水线寄存器,得到PIPE-处理器:
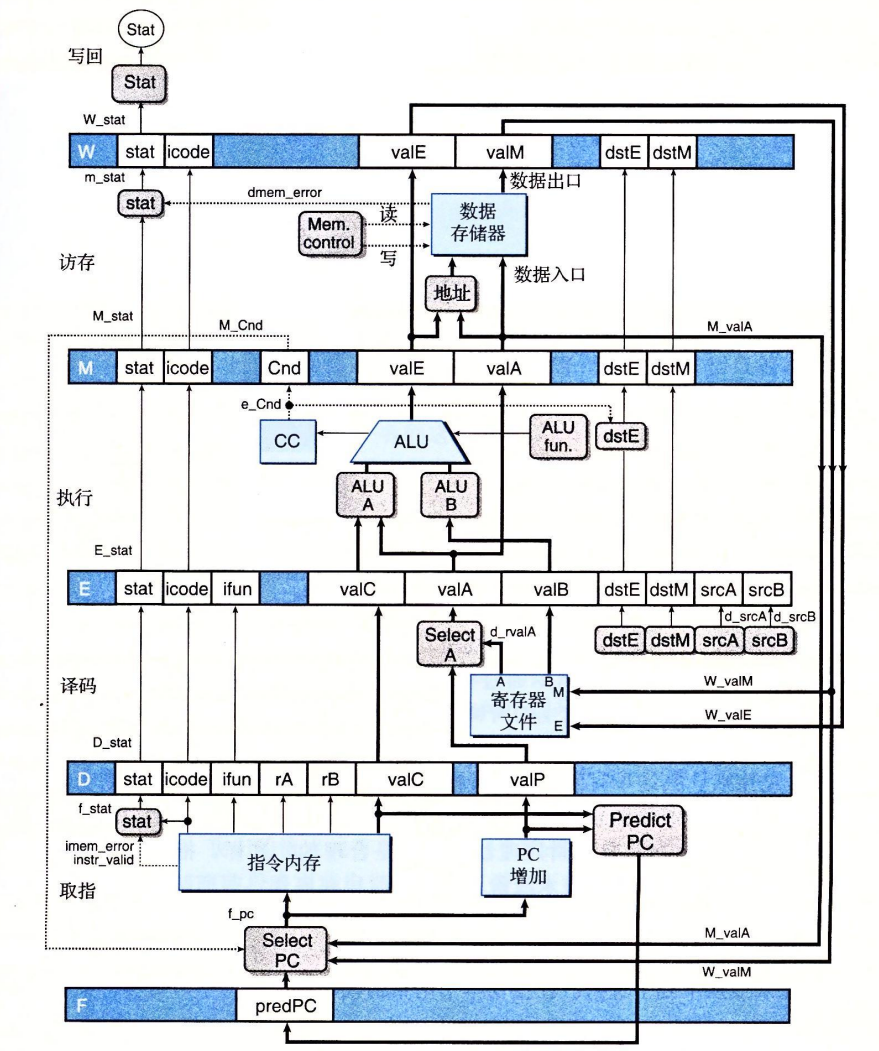
流水线寄存器按如下方式编号:
- F:保存程序计数器的预测值。
- D:位于取指和译码阶段之间,保存关于最新取出的指令的信息,即将由译码阶段进行处理。
- E:位于译码和执行阶段之间,保存关于最新译码的指令和从寄存器文件读出的值的信息,即将由执行阶段进行处理。
- M:位于执行和访存阶段之间,保存最新执行的指令的结果,即将由访存阶段进行处理,还保存关于用于处理条件转移的分支条件和分支目标的信息。
- W:位于访存阶段和反馈路径之间,反馈路径将计算出来的值提供给寄存器文件写,而当完成ret指令时,它还要向PC选择逻辑提供返回地址。
M_stat与m_stat的区别:
在命名系统中,大写的前缀“D”、“E”、“M”、“W”指流水线寄存器,所以M_stat指代流水线寄存器的状态码字段。而小写的前缀“f”、“d”、“e”、“m”、“w”值流水线阶段,故m_stat指代在访存阶段中由控制逻辑块产出的状态信号。
在上面我们提到,F寄存器保存着PC的预测值,这是因为我们并不知道是否需要选择条件分支,所以无法马上确定下一条指令的位置,至少要求指令通过执行阶段。为了使处理器保持每个时钟周期执行一条指令的吞吐量,我们需要预测一个PC值。
在这里,我们采取总是预测选择了条件分支的方案,研究表明成功率大约为60%。
另一个是遇到ret指令时,我们需要指令通过访存阶段才能确定返回地址。但与条件转移不同,ret返回栈顶的字,内容可以是任意的。所以我们在设计时不会进行任何预测,只是简单的暂停处理新指令,直到ret指令通过写回阶段。
流水线冒险
在实际过程中,我们还需要考虑指令之间相互关联的情况,即后一指令需要前一指令执行完毕后才能正确运行。一般而言相关有两种形式:数据相关,下一条指令会用到这一条指令计算的结果;控制相关,一条指令要确定下一条指令的位置,例如返回、跳转、调用指令。
这些相关可能造成流水线的计算错误,称为冒险(hazard)。我们首先来处理数据冒险。
下面看一个例子:
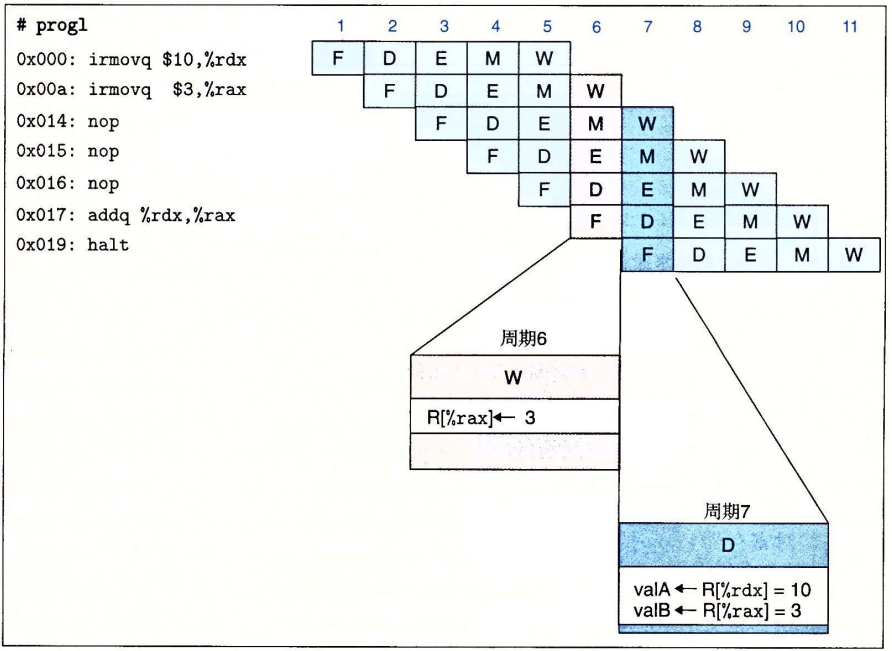
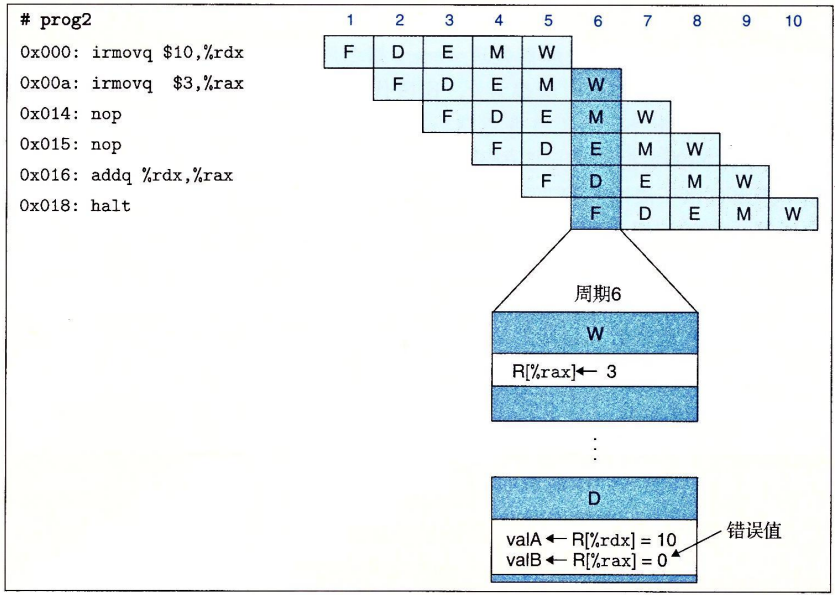
可以看到,在prog2中,由于%rax的值未能正确读取,导致addq产生错误结果。
为了避免这种hazard,我们一般采取以下方法:
暂停(stalling)
暂停时,处理器会停止流水线中一条或多条指令,直到冒险条件不再满足。
用上面的例子来说,当指令addq处于译码阶段时,流水线控制逻辑发现执行、访存或写回阶段中至少有一条指令会更新寄存器
%rdx或%rax,便会将addq阻塞在译码阶段。当然,也要阻塞其后的指令的阶段。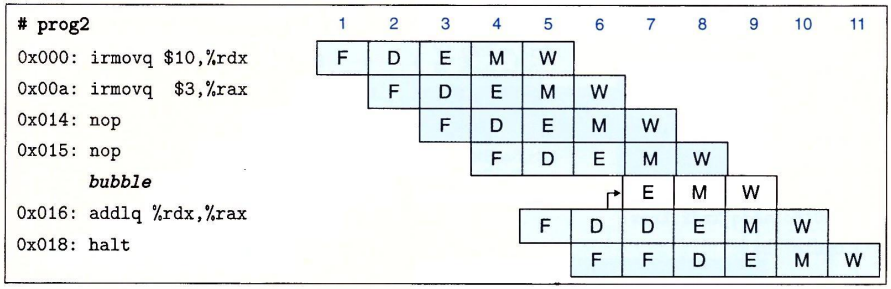
用转发来避免数据冒险
这种策略时将要写入寄存器的值传到流水线寄存器E作为源操作数,也就是说
addq不从%rax中读取操作数,而是直接在写入%rax的同时传递为操作数。这种技术称为数据转发,有时称为旁路。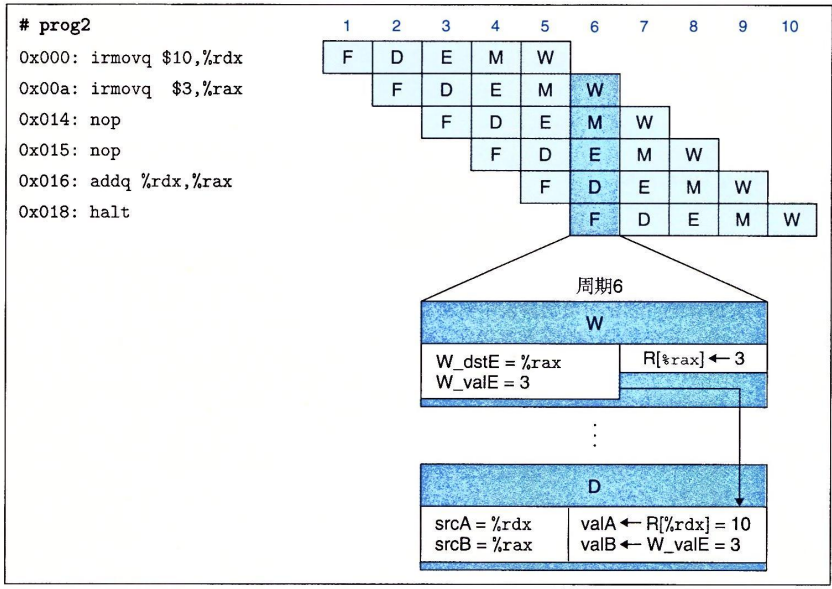
从执行阶段转发:
- 如果执行阶段的 ALU 计算结果
valE是当前指令需要的源操作数,那么直接将valE转发到译码阶段使用。 - 例如,当前指令是
rmmovq,需要源寄存器rA的值,而前一条指令是addq,写入寄存器rA。addq的结果在执行阶段计算完成,可以立即转发给rmmovq。
从访存阶段转发:
- 如果访存阶段的内存读取结果
valM是当前指令需要的源操作数,那么直接将valM转发到译码阶段使用。 - 例如,当前指令是
addq,需要源寄存器rA的值,而前一条指令是mrmovq,从内存中读取值写入寄存器rA。mrmovq的结果在访存阶段获得,可以立即转发给addq。
从写回阶段转发:
- 如果写回阶段的结果是当前指令需要的源操作数,那么直接将写回结果转发到译码阶段使用。
- 例如,当前指令是
subq,需要源寄存器rB的值,而前一条指令是rmmovq,结果将写回寄存器rB。rmmovq的结果在写回阶段可以立即转发给subq。
- 如果执行阶段的 ALU 计算结果
加载/使用数据冒险
有一类数据冒险不能单纯用转发来解决,因为内存读在流水线发生的比较晚。这时我们选择将暂停和转发结合起来,通过适当的暂停来处理加载/使用冒险,这种方法叫加载互锁。
例如下面这个例子:
1
2
3mrmovq 0(%rdx),%rax
addq %rbx,%rax
halt由于前一条指令涉及到从内存中读取数据,所以需要在第一条指令进行到访存阶段之后再将数据转发到下一条指令,中间需要先进行暂停,再进行转发。
避免控制冒险
一般来说,控制冒险只会发生在ret指令和跳转指令。并且只有在条件跳转方向预测错误时才会造成麻烦。
以下面这段代码为例:
1
2
3
4
5
6
7
8
9
10irmovq stack,%rsp
call proc
irmovq $10,%rdx
halt
.pos 0x20
proc:
ret
rrmovq %rdx,%rbx
.pos 0x30
stack:我们看看流水线图:
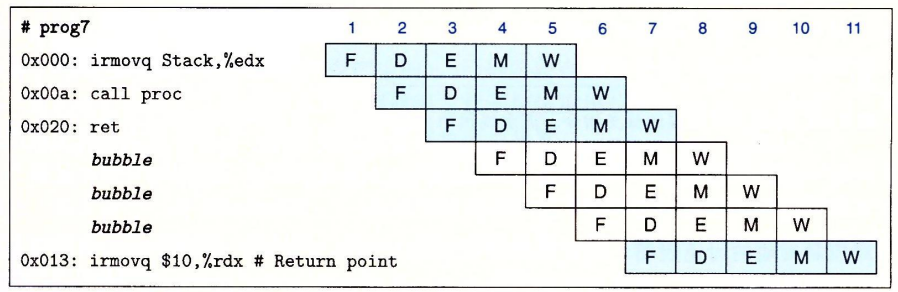
这里在ret指令执行时,其它的指令都会暂停,结束时将PC设置为位于返回点的irmovq指令。要处理预测错误的分支,可以考虑下面这段代码:
1
2
3
4
5
6
7
8xorq %rax,%rax
jne target
irmovq $1,%rax
halt
target:
irmovq $2,%rdx
irmovq $3,%rbx
halt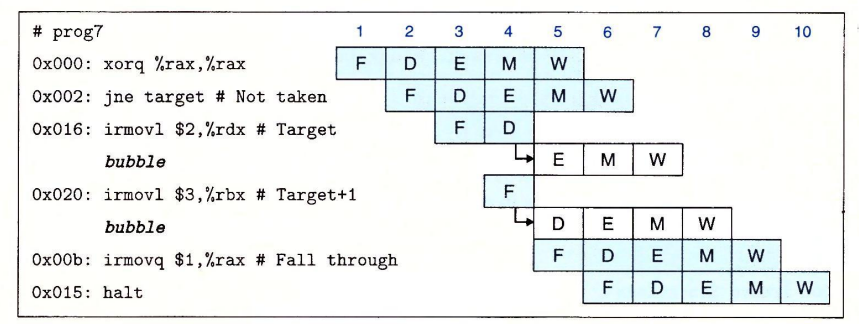
可以看到,由于我们采取默认跳转策略,在第二条指令进入执行阶段(E)时,已经有两条指令开始执行。幸运的是它们并没有导致程序员可见的状态码发生变化,因此我们只要下一个周期向译码和执行阶段插入气泡,同时取出跳转指令后面的指令,这样就能达到取消的作用。
前面避免hazard的方法,多次使用到暂停和保存寄存器信号的操作。在硬件层面上,我们通过向流水线寄存器多输入两个控制信号:stall和bubble。当stall信号设置为1时,寄存器会一直保持当前状态;当bubble信号为1时,寄存器会被设置为等效于指令nop的复位配置状态。
异常处理
我们的指令集体系结构包括三种不同的内部产生的异常:1)halt指令,2)有非法指令和功能码组合的指令,3)取指或数据读写试图访问一个非法地址。
在出现异常时,我们需要暂停异常指令的后续所有指令,其中我们需要注意以下的细节:
- 多个异常,优先报告流水线中最深的。
- 应该取消的指令(不被选择的分支中的指令)导致了异常。
- 异常指令的后续指令在异常指令完成前改变了某些状态。
PIPE各阶段的实现
PC选择和取指阶段
在这个阶段,重点在于如何得到PC的值。一般而言,我们根据
icode的类型,可以将指令分为两大类:- 顺序执行,如
halt,nop,movq,Opq,pushq,popq等。此时,我们计算的PC值为:$valp=PC+length$,即前一个PC加上指令的长度。 - 跳转执行,如
call,jxx等,我们需要进行预测。一种情况是ret指令,此时直接将valC作为下一个PC地址,在这里我们读取W_icode,W_valM;另一种情况需要结合前面指令的译码、执行、访存阶段的运行结果来判断是否选择条件分支,这里我们一般需要读取M_icode,M_Cnd,M_valA来判断。
- 顺序执行,如
译码阶段
由字段rA和rB读取寄存器ID,经过srcA和srcB逻辑单元输入到寄存器文件,用valA和valB表示译码结果。在这里我们需要判断是使用转发的数据还是从寄存器中读取数据,判断的依据是根据当前需要读取寄存器ID值与转发的目的寄存器的ID值是否相等。
第一个转发源是ALU的输出结果
e_dstE,e_valE。第二个转发源是内存的输出数据M_dstE,M_valE。第三个转发源是访存阶段时对寄存器写入端口E还没有进行写入的数据M_dstM,m_valM。第四个转发源是写回阶段时,对寄存器写入端口M和E还没进行写入的数据W_dstM,w_valM,W_dstE,w_valE。优先级按照EMW的阶段排序。执行和访存阶段
在这两个阶段中,指令进入到ALU单元进行计算得到valE和改变条件码进行执行,之后从valP和valA中选择得到valM。
除了基本阶段的实现,我们还需要处理特殊情况:
加载/使用冒险
1
2mrmovq 0(%rdx),%rax
addq %rbx,%rax对于指令
addq,我们希望其阻塞在译码阶段(D)。具体的解决方法是:阶段 F D E M W 加载/使用数据冒险 Stall Stall Bubble Normal Normal 分支预测错误/跳转:
阶段 F D E M W 预测错误的分支 Normal Bubble Bubble Normal Normal 处理ret Stall Bubble Normal Normal Normal 控制条件的组合
1
2
3jne target
irmovq $1,%rax
target:ret由于我们采取总是选取分支的策略,假设预测错误,针对这种组合指令,我们需要另一种方案:
阶段 F D E M W 组合指令1 Stall Bubble Bubble Normal Normal 1
2mrmovq 0(%rdx),%rsp
ret阶段 F D E M W 组合指令2 Stall Stall Bubble Normal Normal
性能分析
引入CPI的概念,指一条指令执行所需要的时钟周期数。
假设处理器在一段时间内处理了$C_i$条指令和$C_b$个气泡,那么大约一共需要$C_i+C_b$个时钟周期。我们得到CPI的计算公式:
$$
CPI=\frac{C_i+C_b}{C_i}=1.0+\frac{C_b}{C_i}
$$
后一项视为惩罚项,代表平均每条指令需要插入的气泡数。我们把这一项进一步分解:
$$
CPI=1.0+lp+mp+rp
$$
其中lp代表由于加载/使用冒险暂停时插入的气泡平均数,mp表示分支预测错误取消指令时插入的气泡平均数,rp表示返回指令暂停时插入的气泡平均数。
优化程序性能
对应原书第五章
程序性能表示
我们引入度量标准:每元素的周期数(Cycles Per Element, CPE),作为一种 表示程序性能的指标。
一般而言,CPE可以用下面的式子来表示:$\Large CPE=\frac{程序运行的总CPU周期数}{处理的数据元素个数}$
利用最小二乘法进行拟合,取元素个数为横轴,我们一般会得到形如$y=kn+C$的表达式。其中,线性因子$k$就是我们的CPE。
优化性能的基本原则
在优化函数性能时,最常见的有几种情况:
内存别名引用
1
2
3
4
5
6
7
8
9
10void twiddle1(long *xp, long *yp)
{
*xp += *yp;
*xp += *yp;
}
void twiddle2(long *xp, long *yp)
{
*xp += 2 * (*yp);
}考虑上面的两个函数,在xp和yp指向不同地址的情况下,函数1需要进行6次内存访问,而函数2仅需要进行3次。但是如果xp和yp指向了同一内存地址,那么就不需要这么多次的内存访问操作。所以编译器在优化时,需要假设不同的指针会指向同一个内存位置。
函数调用
1
2
3
4
5
6
7
8
9long f();
long func1()
{
return f()+f()+f()+f();
}
long func2()
{
return 4 * f();
}乍一看,func1可以被优化为func2的形式。但是考虑到我们下面这种情况:
1
2
3
4
5
6long counter = 0;
long f()
{
return counter++;
}调用函数f会导致全局变量的改变,而全局变量与函数的调用次数相关。在这种情况下,func1的结果是6,而func2的结果是0 。编译器首先会保证程序的正确性,因此在遇到这种情况时会保持所有的函数调用不变。
为了进一步进行说明,我们举一个具体的例子,来看看程序是如何被系统进行优化的。我们将使用一个向量数据结构来进行演示,该数据结构包括两个内存块——头部和数据结构,data_t表示存储的数据类型,len储存在头部,表示数组的长度。
我们设定一个算法,用来将一个向量中的所有元素合并成一个值。接下来我们对该算法进行逐步的优化来体会程序是如何被优化的。其中含有两个方法函数vec_length和get_vec_element,这里不写出具体定义。
1 | |
消除循环的低效率
首先我们注意到for循环会调用函数
vec_length,并且是每次循环调用一次。由于该函数的结果是一定的,所以我们可以先将结果保存下来在传入for循环内部:1
2
3
4
5
6
7
8
9
10
11
12void conbine2(vec_ptr v, data_t *dest)
{
long i;
*dest = IDENT;
long length = vec_length(v);
for(int i = 0; i < length ; i++)
{
data_t val;
get_vec_element(v,i,&val);
*dest = *dest OP val;
}
}这个优化被称为代码移动,一般用于识别要执行多次但是计算结果不会改变的计算。对于一些会产生副作用的函数,程序员需要帮助编译器进行显式地代码移动。
减少过程调用
我们继续看
combine2的代码,发现每次循环均会调用函数get_vec_element。在实现这个函数的过程中,每次需要将向量索引i与边界进行比较。分析代码可知由于for循环限制了i的范围是0~len,这确保了不会造成越界,因此我们可以将get_vec_element中判断是否越界的代码删去。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16data_t *get_vec_start(vev_ptr v)
{
return v->data;
}
void combine3(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
*dest = IDENT;
for(i = 0 ; i < length; i++)
{
*dest = *dest OP data[i];
}
}然而性能并没有明显提升,这显然是循环中的其它操作形成了瓶颈。我们继续来探究。
消除不必要的内存引用
我们假定数据类型为double,运算为乘法,从combine3的汇编代码入手来检查:
1
2
3
4
5
6
7
8# dest in %rbx, data+i in %rdx, data+length in %rax
.L17:
vmovsd (%rbx), %xmm0
vmulsd (%rdx), %xmm0, %xmm0
vmovsd %xmm0, (%rbx)
addq $8, %rdx
cmpq %rax, %rdx
jne .L17我们可以发现,每次迭代时,积累变量的数值(此处为指针dest指向的地方,该数值的作用是计算出最终的结果)都要先从内存中读出再写入内存,这样的操作是不必要的,因为每次迭代开始时从指针dest读出的值就是上次迭代最后写入的值。所以我们可以先用一个变量专门储存积累变量的数值,而不是用指针
*dest,因为指针必然会引起内存的读写。我们把
*dest变为一个变量acc:1
2
3
4
5
6
7
8
9
10
11
12void combine4(vec_ptr v , data_t *dest)
{
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for(i = 0; i < length; i++)
{
acc = acc OP data[i];
}
*dest = acc;
}
循环展开
循环展开是一种程序变换,通过增加每次迭代计算的元素的数量,减少循环的迭代次数。我们采用$2 \times 1$循环展开的方式改写代码:
1 | |
我们把这个思想归纳为对一个循环按任意因子$k$展开,由此产生$k \times 1$循环展开。为此上限设置为$n-k+1$,再循环内对元素$i$到$i+k-1$应用合并运算,每次迭代循环索引$i \rightarrow i+k$。最后还剩余不足$k$次运算我们再用一个循环来进行合并。
提高并行性
对于之前的代码,我们将积累值存放在acc中,这意味着再前面的计算完成之前,都不能计算acc的新值。所以我们可以采取另外的方式来提高并行性。
多个积累变量
对于一个可结合和可交换的合并运算,我们可以通过将一组合并运算分割成两个或更多的部分,最后合并结果来提高性能。
1 | |
像上面这种操作我们称为$2\times2$循环展开。同样的,我们可以引申出$k \times k$循环展开
重新结合变换
我们看到combine5函数中并没改变合并向量元素形成和或者乘积中执行的操作,我们可以考虑从根本上改变合并执行的方式,来提高程序的性能。
我们将combine5中执行合并的语句改为:
1 | |
差别仅仅在于括号的放置位置。我们称为重新结合变换,这样产生了我们称为$2\times 1a$的循环展开方式。看上去这两个语句本质上没有差别,但实际上,如果我们先计算acc OP data[i]再计算一次乘法,需要等待前一次的迭代累计值计算完毕后才能执行下一次的乘法,而先计算data[i] OP data[i+1]则不需要等待。
存储器层次结构
对应原书第六章
储存技术
我们首先从各种储存技术开始介绍。
随机访问存储器
随机访问存储器(Random-Access Memory, RAM)分为两类:静态和动态。静态RAM(SRAM)比动态RAM(DRAM)更快,但是更加昂贵。SRAM常用于作为高速缓存存储器,既可以在CPU芯片上,也可以在片下。DRAM用来作为主存以及图形系统的帧缓冲区。
SRAM
SRAM将每个位存储在一个双稳态(bistable)的存储单元内。这意味着它可以无限期地保持着在两个不同的状态之一,其他任何状态都会迅速的转移到这两个状态之一。
DRAM
DRAM将每个位储存为对一个电容的充电。每个单元有一个电容和一个访问晶体管组成。DRAM对干扰比较敏感,电容的电压被干扰之后,永远不会恢复。
传统的DRAM
DRAM中的单元被分成d个超单元,每一个超单元都有w个DRAM单元组成。一个$d\times \omega$的DRAM储存了$d\omega$位信息。超单元被组织成一个r行c列的长方形阵列,这里rc=d。每个超单元有形如(i,j)的地址。
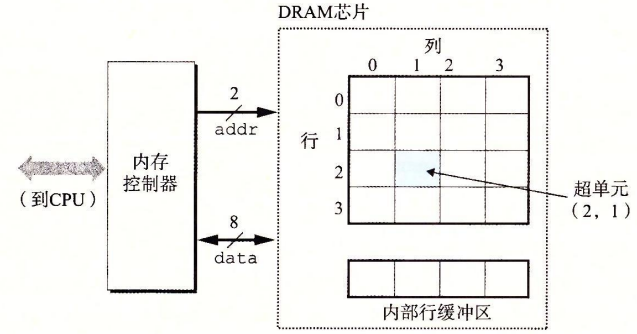
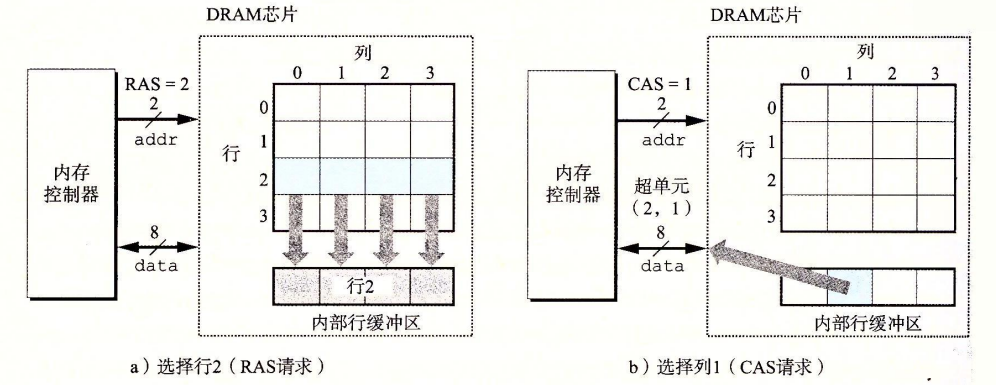
每个DRAM芯片被连接到某个称为内存控制器的电路,这个电路可以一次传送$\omega$位到每个DRAM芯片或者一次从每个DRAM芯片传出对应位。为了读出超单元(i,j)的内容,内存控制器需要发送两个地址到DRAM,然后DRAM将对应地址的内容发回控制器。行地址和列地址记为RAS和CAS。
内存模块
DRAM芯片封装在内存模块DRAM中。一个内存模块包含多块DRAM芯片,当取出内存地址A处的一个字时,内存控制器将A转换成一个超单元地址(i,j),每个DRAM输出该超单元的数据内容,模块中的电路收集这些输出,并把它们合并成一个64位字,再返回给内存控制器。
通过将多个内存模块连接到内存控制器,能够聚合成主存。在这种情况中,控制器需要选择包含A的模块k并发送,而不是收集所有DRAM的响应。
增强的DRAM
- 快页模式(FPM DRAM)。FPM DRAM允许对同一行连续地访问。例如我们需要访问第四行的多个超单元,这时我们不需要传送多次信号RAS/CAS信号,只需要传送一个RAS信号和多个CAS信号即可。
- 扩展数据输出(EDO DRAM)。在FPM的基础上进行改进,允许CAS信号在时间上靠得更紧凑。
- 同步DRAM(SDRAM)。常规的DRAM都是异步的。
- 双倍数据速率同步(DDR DRAM)。使用两个时钟沿作为控制信号,从而使DRAM的速度翻倍。
- 视频RAM(VRAM)。与FPM DRAM类似,用帧缓冲区中的像素刷新屏幕。(不深入了解)
非易失性存储器
缎带你情况下,DRAM和SRAM会丢失它们的信息,而非易失行存储器可以在关电后保存信息。
访问主存
总线是一组并行的导线,能够携带地址、数据和控制信号。取决于总线的涉及,数据和地址信号可以共享同一组导线,也可以不同。
我们考虑CPU执行
movq A,%rax指令时加载操作会发生什么。首先,CPU将地址A放到系统总线上,I/O桥将其传递到内存总线。接下来,主存收到地址信号,从内存总线读地址,并从DRAM中取出数据写到内存总线。I/O敲将内存总线信号翻译成系统总线信号,传递到CPU,CPU将数据复制到寄存器%rax。
磁盘存储
磁盘构造
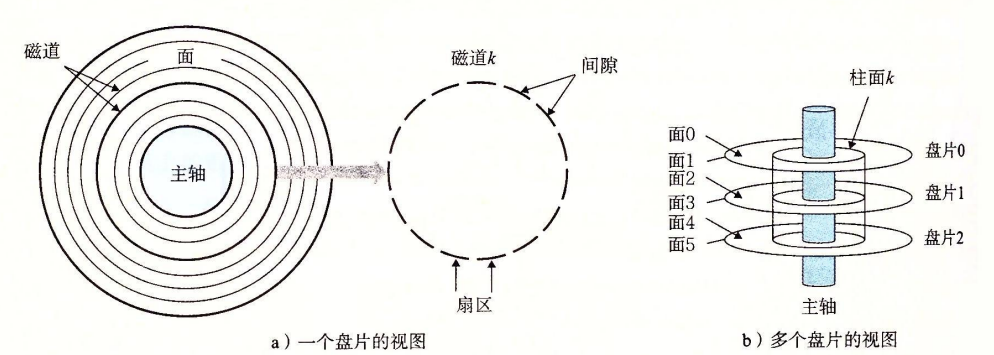
磁盘由盘片构成,每个盘片由两面或称为表面构成,表面覆盖磁性记录材料。盘片中间有一个可以旋转的主轴,它使盘片以固定的旋转速率旋转。
每个表面由一组称为磁道的同心圆组成,每个磁道被划分为一组扇区,每个扇区包含等数量的数据位(通常是512字节)。扇区间由一些间隙隔开。
磁盘容量
一个磁盘上可以记录的最大位数称为它的最大容量,由以下几个因素决定:记录密度、磁道密度、面密度。线代的磁盘使用多区记录的技术,将柱面的集合分割成不相交的子集合,称为记录区,每个区包含一组连续的柱面,每个柱面的每条磁道含有相同数量的扇区。
$$
磁盘容量=\frac{字节数}{扇区}\times \frac{平均扇区数}{磁道}\times \frac{磁道数}{表面}\times \frac{表面数}{盘片} \times \frac{盘片数}{磁盘}
$$
对于一个5个盘片、每个扇区512字节、每个面20000条磁道,每条磁道平均300个扇区的磁盘,容量为:
$$
Volume=\frac{512字节}{扇区}\times \frac{300扇区}{磁道}\times \frac{20000磁道}{表面}\times \frac{2表面}{盘片}\times \frac{5盘片}{磁盘}=30.72GB
$$
其中,单位的换算关系为:$1GB=10^9\quad bytes,1TB=10^{12} \quad bytes$磁盘操作
磁盘用读/写头来读写存储在磁性表面的位,而读写头连接到一个传动臂一端,可以将其定位到磁道上,这称为寻道。读取速度取决于寻道时间、旋转时间、传送时间。
逻辑磁盘块
现代磁盘将它们的构造呈现为一个简单的视图,一个B个扇区大小的逻辑块的序列,编号从0到B-1.磁盘中封装了一个磁盘控制器,维护逻辑块合物理磁盘扇区之间的映射关系。
当操作系统需要进行一个I/O操作时,操作系统将命令发送到磁盘控制器,控制器将逻辑块号翻译成一个(盘面,磁道,扇区)的三元组。
局部性
局部性指程序倾向于引用邻近于其它最近引用过的数据项的数据项或数据项本身。这可以作为衡量程序性能的一项重要指标。
局部性通常分为时间局部性合空间局部性。我们从程序数据引用为例来简单了解一下:
1 | |
对于变量sum而言,在每次循环中杯引用一次,具有时间局部性。另一方面对向量v而言,其中的元素是按顺序读取的,所以具有良好的空间局部性。特别地,对于像这样顺序访问一个向量的每个元素的函数,我们称其具有步长为1的引用模式,也叫顺序引用模式。同理,我们延申出步长为k的引用模式。
因此,我们可以得出一般性的结论:重复引用相同变量的函数具有良好的时间局部性,同时引用步长越小,程序的空间局部性越强。
多级存储结构
现代计算机中,存储器按照一定的层次结构进行组织。
存储器层次结构的中心思想是,对于每个k,位于k层的更快更小的存储设备作为位于k+1层更大更慢的存储设备的缓存。换句话说,层次结构中的每一层都缓存来自较低一层的数据对象。
缓存
我们可以看到,在层次结构中有许多“缓存结构”。一般而言,高速缓存(cache)是一个小而快速的存储设备,它作为存储在更大、更慢的设备中的数据对象的缓冲区域,使用高速缓存的过程称为缓存(caching)。
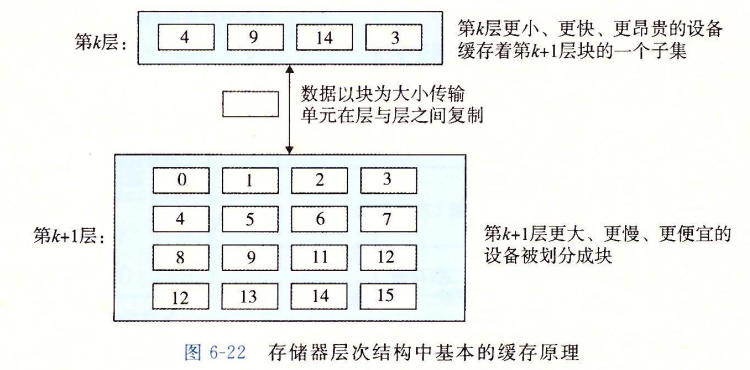
每一层的存储器被划分为固定大小或可变大小的数据块,而数据总是以块为大小在层之间来回复制。一般相邻的层之间块的大小是固定的,而其它的层次对之间可以有不同的块的大小。
缓存命中/不命中
当程序需要第k+1层的数据对象d时,它首先在当前存储在第k层的一个块中查找d。若d恰好在第k层,我们称为缓存命中,这时程序直接从第k层读取速度更快。另一方面,若缓存不命中,第k层的缓存会从第k+1的缓存中取出包含d的块,覆盖掉现存的块,这称为替换或驱逐。
缓存不命中分为多种情况,其中特别的,若第k层是空的,我们称之为冷缓存,此类不命中称为强制性不命中或冷不命中。
只要发生了不命中,第k层的缓存就需要采取某个放置策略来确定k+1层取出的块放在哪里。一般而言,硬件缓存采取严格的放置策略,即将k+1层的某个块限制放置在第k层块的一个小子集中。这种策略会引起一种不命中,称为冲突不命中。例如,我同时需要第k+1层两个块的两个数据,但是这两个数据按照策略被保存在第k层同一个块,这样会导致一直循环,对这两个块的每次引用都不会命中。
另一种是容量不命中,即第k层的块的数量不足以处理所有的数据,也就是缓存太小了。
高速缓存存储器
考虑一个计算机系统,其中每个存储器地址有m位,形成$M=2^m$个不同的地址。这样的一个机器的高速缓存被组织成一个有$S=2^s$个高速缓存组的数组。每个组包含E个高速缓存行。每个行有一个$B=2^b$字节的数据块组成的,还有1个有效位和$t=m-(b+s)$个标记位,它们唯一地表示存储在这个高速缓存行中的块。
一般而言,高速缓存的结构可以用元组(S,E,B,m)来描述。高速缓存的大小C指所有块的大小和。标记位和有效位不包括在内,因此$C=S\times E\times B$。
参数S和B将m个地址分为了三个字段:t个标记位,s位组索引,b位块偏移。组索引被解释为一个无符号整数,它告诉我们这个字必须存储在哪个组中。一旦我们知道了这个字存放的组,t个标记位就告诉我们组的哪一行包含这个字,确定行后b个块偏移位给出了在B个字节的数据块中的子偏移。
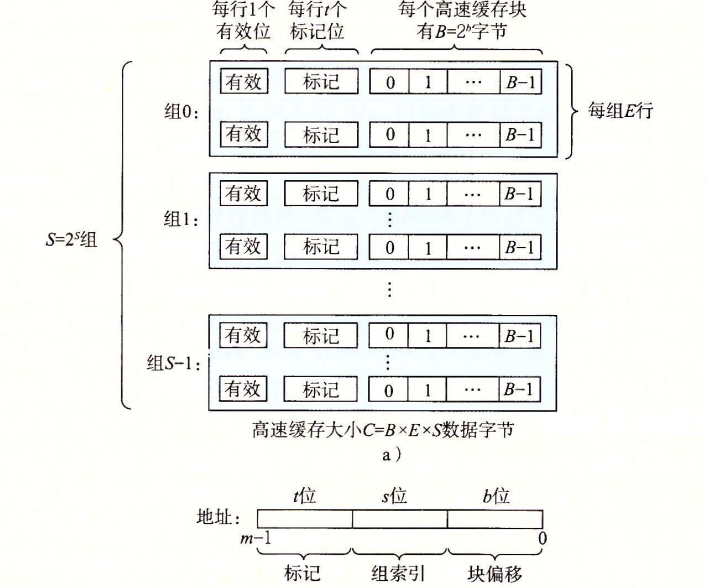
直接映射高速缓存
根据每个组的高速缓存行数,高速缓存被分为不同的类。每个组只有一行(E=1)的高速缓存称为直接映射高速缓存。这是最容易理解和实现的一种高速缓存。
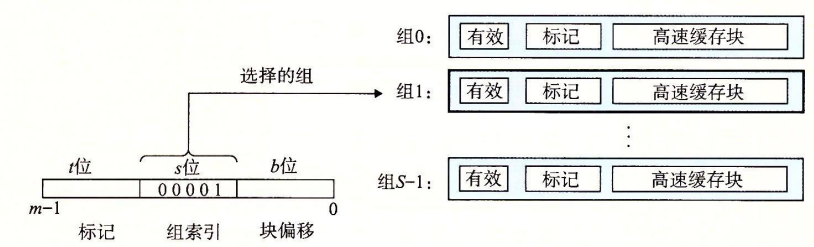
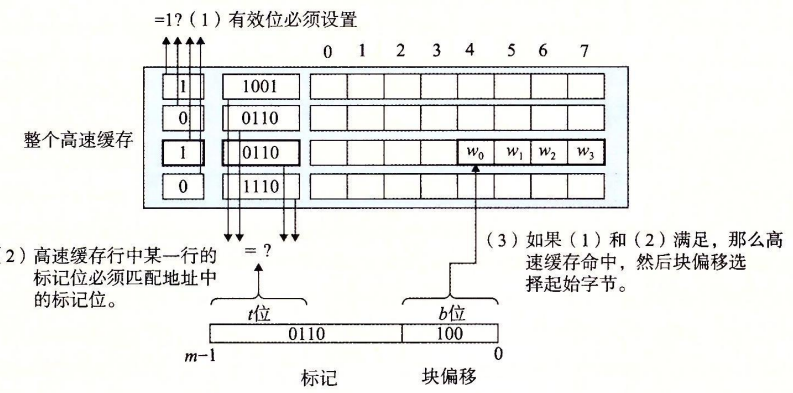
假设我们有这样一个系统,由一个CPU,一个Register,一个L1高速缓存和一个主存组成。当CPU执行一条读内存$\omega$的指令,它向L1请求这个字。如果缓存命中,L1会很快抽取出并返回给CPU。若不命中,L1向主存申请一个包含$\omega$块的副本,再返回给CPU。像这样的过程我们可以抽象为三步:1)组选择;2)行匹配;3)字抽取。
组选择
在这一步中,高速缓存从$\omega$的地址中间抽取出s个索引位,并解释为一个无符号整数。
行匹配
在组选择后,我们需要确定是否有$\omega$的一个副本存储在该组包含的一个高速缓存行中。这一步通过匹配高速缓存行中的标记与$\omega$的地址中的标记来实现。如果匹配成功,则缓存命中。若不成功,则为缓存不命中,此时进行行替换很简单,由于每组只有一行,所以直接用新取出的行来替换当前行。
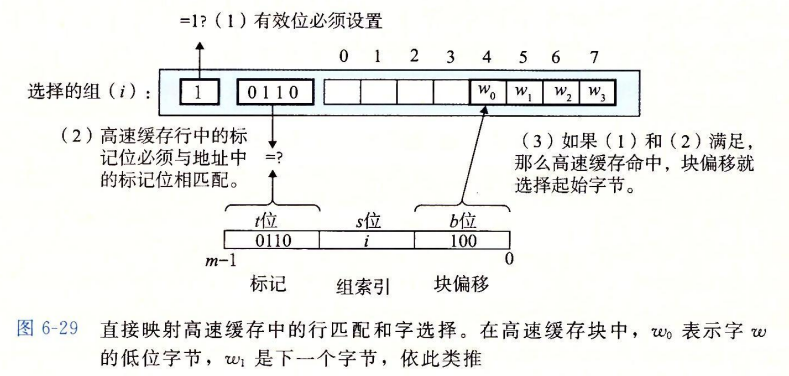
字选择
最后一步需要确定所需要的字在块中从哪里开始,这是由块偏移量b所确定的。
我们以一个直接映射高速缓存来具体进行学习:假设我们有一个这样的高速缓存
$$
(S,E,B,m)=(4,1,2,4)
$$
也就是高速缓存有4组,每组1行,每个块2个字节,地址是4位的。地址和其对应的关系如图:
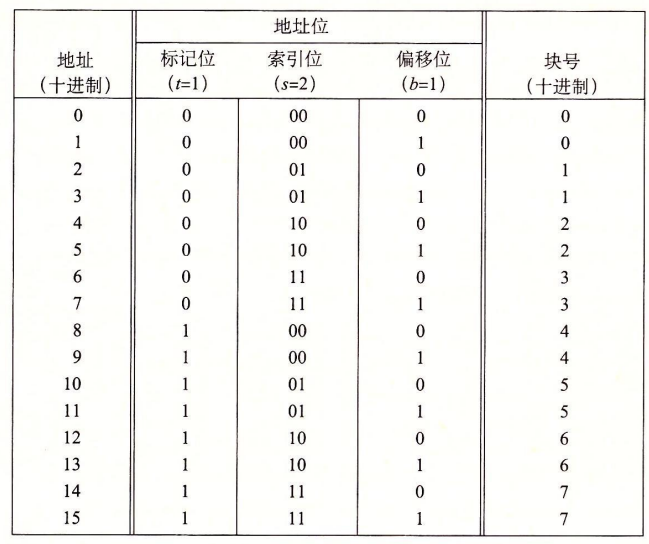
我们注意到:
- 标记位和索引位连起来唯一地标识了内存中的每个块。例如块0由地址0和1组成。
- 多个块会映射到同一个组(即组索引相同)。例如,图中块0和块4都映射到组0。
- 映射到同一个高速缓存组的块应由标记位唯一标识。例如块0的标记位为0,块4的为1,即使组索引位相同。
接下来我们模拟一下CPU是如何从内存中读取内容的,我们假设CPU读取一字节的字。初始时,高速缓存是空的,即有效位均为0:
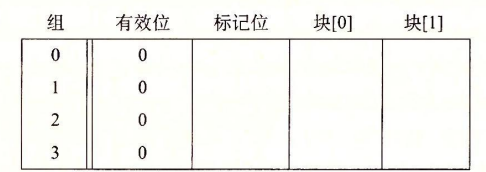
读取地址0的字(0000)
首先进行组选择,中间两位是我们的索引位(00),所以选择组0 。进行行匹配时,由于有效位为0,缓存不命中,从内存取出块0并存放到高速缓存的组0。之后进行字选择,由于偏移量为0,所以选择m[0]返回。
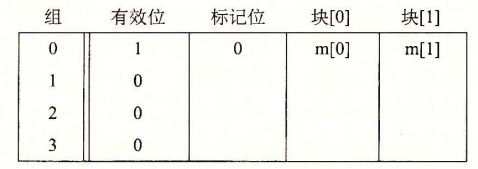
读取地址1111:这是缓存命中,直接返回。
读取地址1101
由于缓存不命中,高速缓存把块6(110)加载到组2,返回m[13]。
读取地址1000:
组0的标记此时为0,与1不匹配,因此缓存不命中。高速缓存将块4加载到组0,然后返回m[8]。

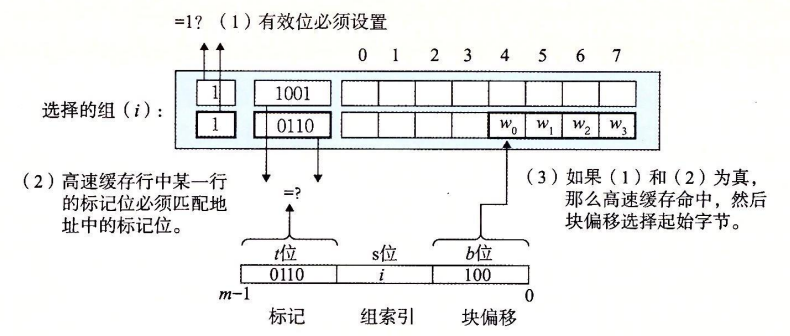
组相联高速缓存
相对的,组相联高速缓存的每一组都有多行。一个$1<E<C/B$的高速缓存通常被称为E路组相联高速缓存。对应的,CPU从内存中读取数据时也可以分为三步:组选择、行匹配、字选择。
全相联高速缓存
全相联高速缓存是由一个包含所有高速缓存行的组(E=C/B)。也就是整个高速缓存只有一个组0.所以这时便不需要组选择,地址只有标记位和块偏移。
为什么用中间位作为索引位
我们假设地址为4位,索引位为中间2位,那么中间位索引和高位索引的区别可以由下图所示:
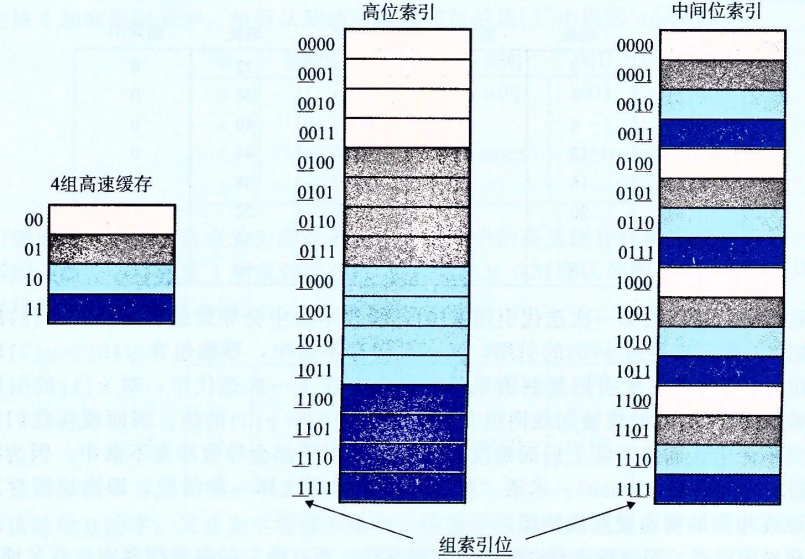
可以看到,相比于高位索引,使用中间位索引能够将相邻的块映射到不同的高速缓存行,这样在顺序读取时能够极大提高效率。
编写高速缓存友好的代码
在之前的学习中,我们了解到了局部性的思想。结合高速缓存的存储原理,我们可以发现,局部性比较好的程序更容易有较低的不命中率,而这导致程序的性能更优。为了写出高速缓存友好的代码,我们需要遵循以下的一些基本原则:
- 让最常见的情况运行得快。程序通常把大部分时间花在少量的核心函数上,而这些函数通常把大部分时间都花在了少量循环上。因此我们需要将注意力集中在核心函数里的循环上,而忽略其他部分。
- 尽量减少每个循环内部的缓存不命中数量。
我们将之前的函数拿出来作为例子来说明:
1 | |
首先对于局部变量i和sum,具有良好的时间局部性。事实上,由于它们是局部变量,编译器会将它们缓存在寄存器文件中。之后考虑对向量v的步长为1的引用。一般而言,对于步长为k的引用模式,平均每次循环会有$min(1,(wordsize\times k)/B)$次缓存不命中。当k=1时,取最小值,因此对于v的步长为1的引用是高速缓存友好的。
因此编写高速缓存友好的代码需要注意:
- 对局部变量的反复引用是好的,因为编译器能将它们缓存在寄存器文件中(时间局部性)
- 步长为一的引用模式是好的,因为所有层次的缓存都是将数据存储为连续的块。
我们再来考虑一个二维数组的例子:
1 | |
由于C语言以行优先顺序存储数组,因此我们会有和步长为1的引用模式相同的命中模式:每4次访问一次不命中,不命中率为25%。
但是假设我们交换行列循环的次序:
1 | |
在这种情况下,最好的是我们的整个数组都保存在高速缓存中,这样会有相同的不命中率25%。如果数组大于高速缓存,我们对$a[i][j]$的每次访问都不会命中!

链接
对应原书第七章
链接(Linking)是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载到内存并执行。链接可以执行于编译时(compile time),也可以执行于加载时(load time),甚至执行于运行时(run time)。在早期,程序员手动执行链接,在现代系统中,链接是由叫做链接器(linker)的程序自动执行的。
在本章中,我们以下面这两个C语言程序作为引子,帮助我们了解链接的工作原理:
1 | |
1 | |
编译器驱动程序
大多数编译系统提供编译器驱动程序,它戴白哦用户在需要时调用语言预处理器、编译器、汇编器和链接器。
对于上面的两个C语言文件,驱动程序大体进行了以下一些步骤:
运行C预处理器(cpp),将C的源程序
main.c翻译成一个ASCII码的中间文件main.i。1
cpp [other arguments] main.c /tmp/main.i接下来,驱动程序运行C编译器(ccl),它将
main.i翻译成一个ASCII汇编语言文件main.s:1
ccl /tmp/main.i -Og [other arguments] -o /tmp/main.s然后,驱动程序运行汇编器(as),它将
main.s翻译成一个可重定位目标文件main.o:1
as [other arguments] -o /tmp/main.o /tmp/main.s驱动程序经过相同的过程生成
sum.o最后运行链接器程序(ld),将
main.o和sum.o以及一些必要的系统目标文件组合起来,创建一个可执行目标文件prog:1
ld -o prog [system object files and args] /tmp/main.o /tmp/sum.o执行文件prog,我们只需要在linux shell 的命令行上输入它的名字:
1
./prog
静态链接与目标文件
像Linux LD程序这样的静态链接器(stack linker)以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的、可以加载和运行的可执行目标文件作为输出。输入的文件以代码和数据节组成,每一节都是一个连续的字节序列,指令在一节中,初始化的全局变量在另一节中。为了构造可执行文件,连接器必须要完成两个任务:
- 符号解析,即将每个符号引用和一个符号定义关联起来。
- 重定位,编译器和汇编器生成从地址0开始的代码和数据节。链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改对所有对这些符号的引用使它们指向这个内存位置。
目标文件也具有三种形式:
- 可重定位目标文件。包含二进制代码和数据,可以在编译时与其它可重定位目标文件合并起来,创建一个可执行目标文件。
- 可执行目标文件。包含二进制代码和数据,可以复制到内存并执行。
- 共享目标文件。一种特殊类型的可重定位目标文件,可以在浇在或者运行时被动态地加载进内存并链接。
现代的 x84-64 Linux和 Unix系统使用可执行可链接格式(Execute-able and Linkable Format,ELF)来组织目标文件。对于一个典型的ELF可重定位目标文件的格式,可以由下图来描述:
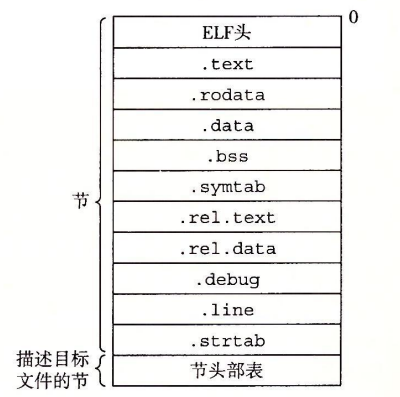
ELF头以一个16字节的序列开始,描述了生成该文件的系统的字的大小和字节顺序。夹在ELF头和节头部表之间的都是节。图中有一些典型的节:
.text:已经编译程序的机器代码.rodata:只读数据,比如printf中的格式串,switch语句的跳转表等。.data:已经初始化的全局变量和static变量。局部变量在运行时被保存在运行时栈中。.bss:未初始化的全局变量和static变量,以及所有被初始化为0的全局变量或static变量。在目标文件中这个节只是一个占位符,不占据实际的空间,只是为了分离已经初始化的和未初始化的变量。.symtab:一个符号表,存放了定义和引用的函数和全局变量的信息,不保存局部变量。.rel.text:一个.text节中位置的列表,当链接器把这个目标文件和其它文件组合时,需要修改这些位置。.rel.data:被模块引用或定义的所有全局变量的重定位信息。.debug:调试符号表,条目时程序中定义的局部变量和类型定义,定义和引用的全局变量,以及C源文件。.line:原始C语言程序中的行号和.text节中机器指令之间的映射。.strtab:一个字符串表,包含.symtab和.debug节中的符号表以及节头部中的节名字。
每个可重定位目标模块m都有一个符号表,它包含m定义和引用的符号信息。在链接器的上下文中,有三种不同的符号:
(1)由模块m定义并能被其他模块引用的全局符号。全局链接器符号对应于非静态的C函数和全局变量。
(2)由其它模块定义并被模块m引用的全局符号。这些符号成为外部符号,对应其它模块中定义的非静态C函数和全局变量。
(3)只被模块m定义和引用的局部符号。对应带static属性的C函数和全局变量。
符号表一般记录了如下的信息:
name:字节偏移,指向符号的字符串名字,如
sumvalue:据定义目标的节的起始位置的偏移。
size:目标的大小,以byte为单位。
type:目标的属性,函数或者数据
section:符号被分配到目标文件的节,同时也是一个到节头部表的索引。其中有三个特殊的标识:ABS,不该被重定位的符号;UNDEF,未定义;COMMON,还未被分配位置的未初始化的数据目标。
对于COMMON和
.bss存放符号的区别,在GCC中,COMMON被指定为未初始化的全局变量,而.bss节中指未初始化的静态变量和初始化为0的全局变量和静态变量。
这里我们举一个练习题的例子来帮助我们加深理解:
1 | |
1 | |
请指出在swap.o中的符号情况:
| 符号 | .symtab条目? | 符号类型 | 在哪个模块定义 | 节 |
|---|---|---|---|---|
| buf | 是,extern声明的全局变量 | 外部 | main.o | .data,已初始化的全局变量 |
| bufp0 | 是,全局变量 | 全局 | swap.o | .data |
| bufp1 | 是,全局变量 | 全局 | swap.o | COMMON,未初始化全局变量 |
| swap | 是,函数 | 全局 | swap.o | .text |
| temp | 否,函数中的局部变量 | \ | \ | \ |
符号解析
链接器解析符号引用的方法是将每个引用与他输入的可重定位目标文件的符号表中的一个确定的符号定义关联起来。对于那些和引用定义在相同模块中的局部符号的引用,符号解析是非常简单明了的,编译器只允许每个模块中每个局部符号有一个定义。
但是对全局符号的引用解析就棘手多了。当编译器遇到一个不是在当前模块中定义的符号时,会首先假设这个符号是在其它某个模块中定义的,生成一个链接器符号表条目,并把它交给链接器处理。如果链接器在其它任何输入模块中都找不到这个被引用符号的定义,就输出一条错误信息并终止。
解析多重定义的全局符号
在多个模块中,可能出现定义同名的全局符号的情况。Linux编译系统采用强/弱符号标注的方法:函数和已初始化的全局变量是强符号,而未初始化的全局变量是弱符号。
根据这一套标注规则,Linux链接器采取下面的规则来处理多重定义的符号名:
- 不允许有多个同名的强符号
- 如果有一个强符号和多个弱符号同名,选择强符号
- 如果有多个弱符号同名,随机选择一个
在前面,我们看到编译器以一个绝对的规则将符号分到COMMON和.bss节,实际上这是由于某些情况下链接器允许多个模块定义同名的全局符号。在编译器翻译某个模块时,遇到一个弱全局符号x,它无法预测其它模块中是否定义了x,应该选择哪一个定义。所以编译器将其分配为COMMON,将选择权交给链接器。若这是一个强符号,则无需担心,可以直接将其分配成.bss。
与静态库链接和解析
目前为止,我们讨论的都是链接器读取一组可重定位目标文件并将其链接起来,形成一个输出的可执行目标文件。实际上还有一种机制,即将所有相关的目标模块都打包成为一个单独的文件,称为静态库(static library),可以作为链接器的输入。当链接器构造一个可执行文件时,只复制静态库中被应用程序引用的目标模块。
实际上,除了静态库这种形式,还有其它的方法:
让编译器辨认出对标准函数的调用。
将所有的标准C函数都存放在一个单独的可重定位目标文件中。例如:libc.o
这种方法的优点是它将编译器的实现和标准函数的实现分离开来,并且仍然对程序员保持适度的便利,然而会造成磁盘空间的浪费(因为每个可执行文件都包含一份标准函数集合的完全副本)
为每一个标准函数船舰一个独立的可重定位目标文件,例如
scanf.o,printf.o等,存放在一个默认目录中。然而这很容易造成遗漏和错误。
而静态库是一些具有共同点的函数的集合,程序只需要将被引用的目标模块复制。在Linux系统中,静态库以一种称为存档(archive)的文件格式保存,后缀为.a。
例如,我们要编译链接下面两端程序:
1 | |
1 | |
要创建这两个函数的一个静态库,我们需要使用AR工具:
1 | |
假设我们有另一个程序使用了libvector.a中的函数:
1 | |
我们需要执行以下的指令将我们的libvector.a链接:
1 | |
这就完成了链接过程。
接下来我们面临的问题就是链接器如何使用静态库来解析引用。在符号解析阶段,链接器会维护三个集合:
- E:可重定位目标文件的集合
- U:未解析的符号,即引用了但是尚未定义的符号
- D:在输入文件中已定义的符号
对于每一个输入文件f,链接器判断其是一个目标文件(.o)还是一个存档文件(.a)。如果是一个目标文件,将其添加到E,修改U和D来反映f中的符号定义和引用。如果是一个存档文件,那么链接器会尝试匹配U中未解析的符号和有存档文件成员定义的符号。如果某个存档文件成员m定义了一个符号解析U中的一个引用,那么将m添加到E,将U中该引用转到D。当所有文件扫描完成之后,U是非空的,说明遇到错误,程序终止。否则链接器就将E中的目标文件合并、重定位,生成可执行文件。
重定位
一旦链接器完成了符号解析,就将代码中的每个符号引用和正好一个符号定义关联起来。此时,链接器知道输入目标模块中的代码节和数据节的确切大小,可以开始重定位步骤了。在重定位步骤中,将合并输入模块,并为每个符号分配运行时地址。重定位分为两步:
重定位节和符号定义:在这一步中,链接器将所有相同类型的节合并为同一类型的聚合节。例如所有输入模块的
.data节都被合并成为一个.data节,这个节作为输出的可执行目标文件的.data节。然后链接器将运行时内存地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号。这样程序中的每条指令和全局变量都有唯一的运行时内存地址了。
重定位节中的符号引用:在这一步,链接器修改代码节和数据节中对每个符号的引用,使得他们指向正确的运行时地址,要执行这一步,链接器依赖于可重定位目标模块中称为重定位条目的数据结构。
重定位条目
当汇编器生成一个目标模块时,它并不知道数据和代码最终将放在内存中的什么位置,也不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置未知的目标引用,他就会生成一个重定位条目,告诉链接器将目标文件合并成可执行文件时如何修改这个引用。代码的重定位条目存放在.rel.text中,已初始化的数据的重定位条目放在.rel.data中。
在ELF格式中,重定位条目保存了下面的信息:
offset:需要被修改的引用的节偏移。假设有一个重定位条目,
offset的值是0x80483f4,表示需要修改位于文件中偏移量为0x80483f4的某个指令或数据。symbol:标识被修改引用应该指向的符号,通常是一个指向符号表的索引。
type:指定了重定位的类型,表明如何对目标位置进行修改。不同的重定位类型表示不同的重定位方式,比如绝对地址、相对地址或特定架构的特殊重定位方法。
常见的重定位类型有2种:
R_X86_64_PC32:符号的相对32位地址,基于当前指令地址(即PC地址)计算相对偏移,具体方法是PC的地址加上32位值。R_X86_64_32:符号的绝对32位地址,直接使用作为有效地址。
addend:是一个有符号常数,一些类型的重定位需要使用其对被修改的引用的值做偏移调整。它表示一个附加值,用于在符号的值基础上进行加法操作,对符号的地址进行偏移,最终得到用于重定位的具体值。
如果
addend字段的值是10,符号的值是0x400100,那么在重定位过程中,链接器将会把0x400100 + 10 = 0x40010A的值写入到目标位置。
下面来具体了解计算机的重定位算法。我们假设s代表每个节,r代表与节关联的重定位条目,ADDR(s),ADDR(r.symbol)表示运行时地址:
1 | |
这里我们以这一章最初的main和sum函数为例,我们使用OBJDUMP产生main.o的反汇编代码:
1 | |
main函数引用了两个全局符号:array和sum。对每个引用,汇编器产生一个重定位条目显示在引用的后一行上。
重定位PC相对引用
在第六行中,调用了sum函数。call指令开始于节偏移0xe的地方,包括1字节的操作码0xe8,后面跟着对sum的32位PC相对引用的占位符。
我们假设重定位条目的四个字段为:
r.offset=0xf,r.symbol=sum,r.type=R_X86_64_PC32,r.addend=-4。假设链接器已经确定:
ADDR(s)=ADDR(.text)=0x4004d0,ADDR(r.symbol)=ADDR(sum)=0x4004e8使用上面的算法,我们首先计算出引用(实际上就是跳转到sum函数所需要的偏移量)的运行时地址:
refaddr=ADDR(s)+r.offset=0x4004d0+0xf=0x4004df然后更新引用(同上,这里是指存放在0x4004df地址处的偏移量)使其指向sum程序:
*refptr=(unsigned) (ADDR(r.symbol) + r.addend - refaddr)=0x5在得到的可执行目标文件中,call指令便被修改为了如下的重定位形式:
4004de: e8 05 00 00 00 callq 4004e8<sum>执行这条指令时,PC在下一条指令处即
0x4004e3,此时CPU执行以下的步骤:1)将PC压入栈中,2)PC=PC+0x5=0x4004e8这样要执行的指令就是sum的第一条指令。也就是说,这个步骤计算的是
call指令需要跳转的偏移量。重定位绝对引用
我们接下来看第四行,mov指令将array的地址(一个32位立即数值)复制到寄存器
%edi中。假设重定位条目的四个字段为:
r.offset=0xa,r.symbol=array,r.type=R_X86_64_32,r.addend=0。假设链接器已经确定:
ADDR(r.symbol)=ADDR(array)=0x601018那么根据算法,我们可以直接计算得到:
*refptr=0x601018因此在得到的可执行目标文件中,mov指令被修改为:
4004d9: bf 18 10 60 00 mov $0x601018,%edi
可执行文件
下图展示了一个典型的ELF可执行文件中的各类信息:
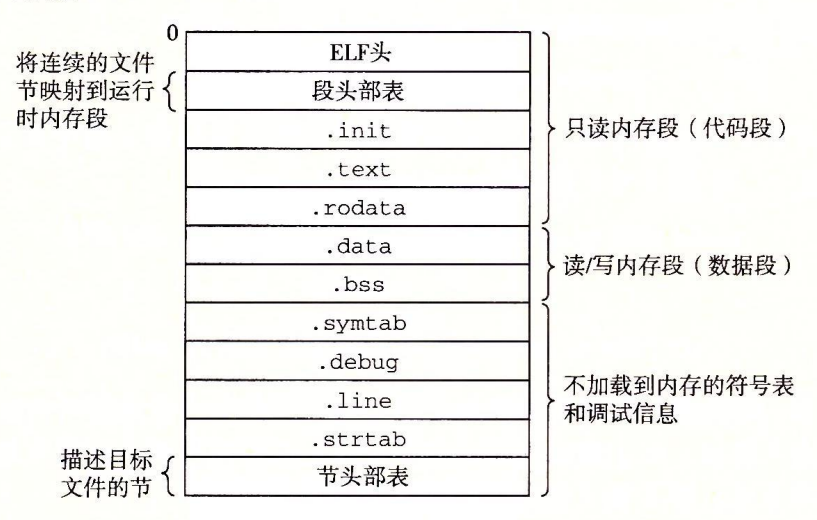
可执行目标文件的格式类似于可重定位目标文件的格式。在里面有一个.init节,在这个节中定义了一个小函数,叫做_init,程序的初始化代码会调用它。因为程序已经是完全链接的(重定位完成),因此不需要.rel节。
可执行文件在设计时使得它很容易加载到内存,可执行文件的连续的片(chunk)被映射到连续的内存片段,程序头部表(program head table)描述了这种映射关系。
要运行可执行目标文件,我们可以在Linux shell 的命令行中输入它的名字:
1 | |
shell通过调用某个驻留在存储器中的称为加载器(loader)的操作系统代码来运行它。任何Linux程序都能调用execve函数来调用加载器,加载器将可执行文件的代码和数据从磁盘复制到内存中,并通过跳转到程序的第一条指令或入口来执行该程序。这个过程被称为加载。
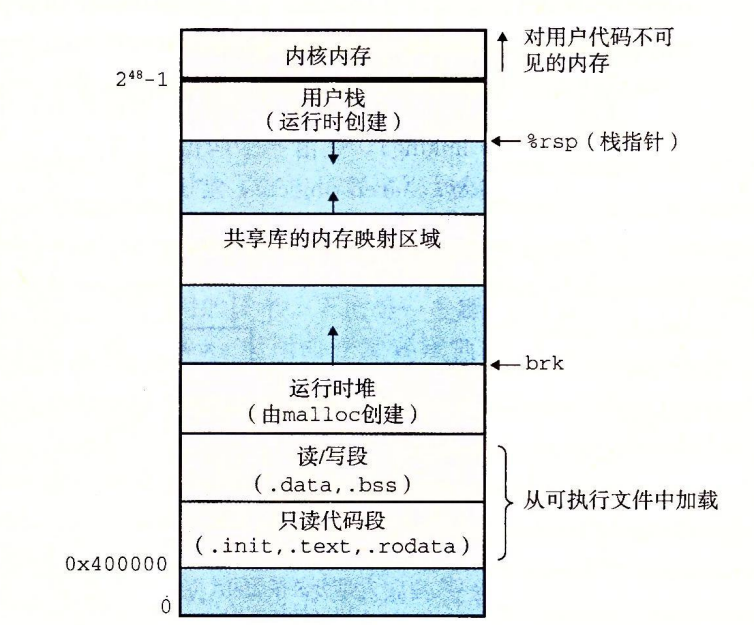
每一个Linux程序都有一个运行时内存映像,由下图所示:
动态链接共享库
静态库解决了我们使用内置函数的问题,但是静态库有一个缺点:需要定义维护和更新。同时,几乎每个C程序都会使用标准I/O函数,例如printf和scanf。在运行时,这些函数的代码会复制到每个运行进程的文本段中,造成内存资源的浪费。
共享库是一个致力于解决静态库问题的现代产物。共享库是一个目标模块,在运行或加载时,可以加载到任意的内存地址,并和一个在内存中的程序链接起来,这个过程叫做动态链接,由动态链接器来执行。
共享库是通过两种不同的方式来进行共享的。首先对于任何给定的文件系统中,对于一个库只有一个.so文件,所有引用该库的可执行文件共享这个so文件中的代码和数据,而不是像静态库的内容那样被复制和嵌入到引用他们的可执行文件中。其次在内存中,一个共享库的.text节的一个副本可以被不同正在运行的进程共享。

基本的思路是当创建可执行文件时,静态执行一些链接,然后再程序加载时,动态完成连接过程。
异常控制流
我们假设程序计数器的值为一个序列$a_0,a_1,\ldots ,a_n-1$。其中,每个$a_k$是某个相应的指令$I_k$的地址。每次从$a_k \rightarrow a_{k+1}$的过渡称为控制转移,这样的控制转移序列叫做处理器的控制流。
最简单的一种控制流只一个“平滑的”序列,其中每个$I_k$和$I_{k+1}$在内存中都是相邻的。但是一些指令可能导致控制流的突变,例如跳转、调用、返回等指令。这样一些指令都是必要的机制,使得程序能够对由程序变量表示的内部程序状态中的变化作出反应。
现代系统通过使控制流发生突变来对系统状态的变化做出反应。一般而言,我们将这些突变称为异常控制流(Exceptional Control Flow,ECF)。
异常
异常是异常控制流的一种形式,它一部分由硬件实现,一部分由操作系统实现。
通俗来讲,异常(exception)就是控制流中的突变,用来响应处理器状态中的某些变化。如图,当处理器状态中发生一个重要的变化时,处理器正在执行某个当前指令$I_{curr}$。在处理器中,状态被编码为不同的位和信号,状态变化称为事件。当处理器检测到事件发生时,会通过一张叫做异常表的跳转表,跳转到异常处理程序,处理完成后要么返回$I_{curr}$,要么返回下一条指令$I_{next}$,要么终止程序。
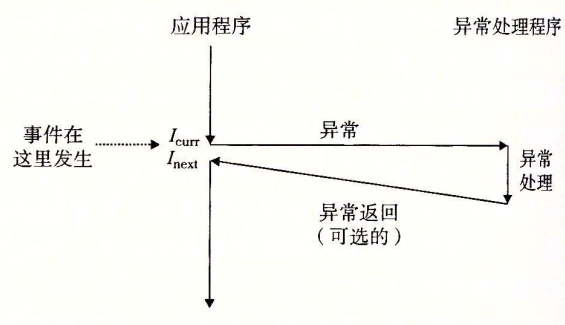
系统为每一种可能的异常分配了一个唯一的非负整数异常号。在系统启动时,操作系统分配和初始化一张称为异常表的跳转表,使表目k包含异常k的处理程序的地址。异常表的起始地址放在一个叫做异常表基址寄存器的特殊CPU寄存器中。
在运行时,处理器检测到发生了一个时间,并确定了异常号k。随后通过异常表的表目跳转到对应的处理程序。
异常可以分为四类:中断(interrupt)、陷阱(trap)、故障(fault)和终止(abort)。
| 类别 | 原因 | 异步/同步 | 返回行为 |
|---|---|---|---|
| 中断 | 来自I/O设备的信号 | 异步 | 总是返回到下一条指令 |
| 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 |
| 故障 | 潜在可恢复的错误 | 同步 | 可能返回到当前指令 |
| 终止 | 不可恢复的错误 | 同步 | 不会返回 |
中断
中断是异步发生的,是来自处理器外部的I/O设备的信号的结果。硬件中断不是由任何一条专门的指令造成的,从这个意义上来说它是异步的。硬件中断的异常处理程序常常称为中断处理程序。
陷阱和系统调用
陷阱是有意的异常,是执行一条指令的结果,这类指令也被称为异常指令。陷阱最重要的用途是在用户程序和内核之间提供一个像过程一样的接口,叫做系统调用。
用户程序经常需要像内核请求服务,比如读一个文件、创建一个新的进程、加载一个新的程序,或者终止当前程序。为了允许对这些内核服务的受控的访问,处理器提供了一条特殊的“syscall n”指令。执行这条指令会导致一个到异常处理程序的陷阱。
故障与终止
故障由错误情况引起,它可能能够被故障处理程序修正。当故障发生时,处理器将控制权交给故障处理程序,如果能够成功修正,控制返回到引起故障的程序,否则返回到内核中的abort例程,终止引起故障的引用程序。
常见的Linux/X86-64系统中的异常
Linux/x86-64故障和终止
包括除零错误(报告为浮点异常,Floating exception)、一般保护故障、缺页、机器检查等。
Linux/x86-64系统调用
在x86-64系统中,系统调用是通过一条称为
syscall的陷阱指令来提供的。所有到Linux系统调用的参数都是通过寄存器而不是栈传递的。按照惯例,寄存器%rax包含系统调用号,寄存器%rdi,%rsi,%rdx,%r10,%r8,%r9包含最多六个参数。下面是一些常见的系统调用实例: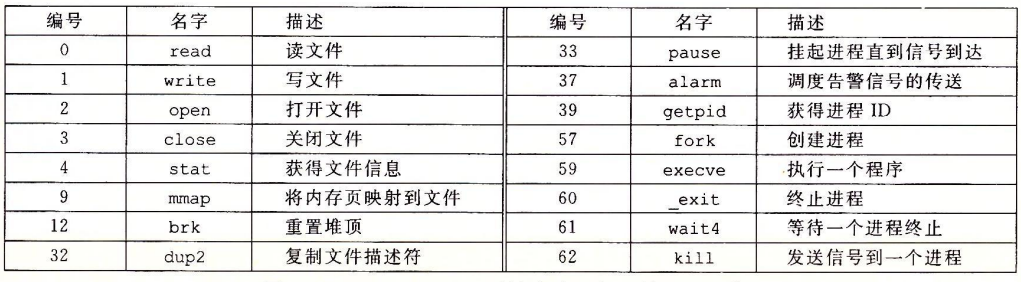
进程
异常时允许操作系统内核提供进程(process)概念的基本构造块。
在现代系统上运行一个程序时,我们会得到一个假象,即当前程序是系统中唯一运行的程序,独占使用处理器和内存。
进程的经典定义就是一个执行中程序的实例。系统中的每个程序都运行在某个进程的上下文(context)中。上下文是由程序正确运行所需要的状态组成的,这个状态包括存放在内存中的程序的代码和数据,它的栈、通用目的寄存器内容、PC、环境变量以及打开文件描述符的集合。
每次用户通过向shell输入一个可执行目标文件的名字,运行程序时,shell就会创建一个新的进程,然后再这个新进程的上下文中运行这个可执行目标文件。应用程序也能创建新进程。
在这里我们不关注实现进程的技术细节,我们仅关注进程提供给应用程序的关键抽象:
- 一个独立的逻辑控制流,让程序看上去在独占使用处理器。
- 一个私有的地址空间,让程序看上去在独占使用内存系统。
逻辑控制流
如果我们用调试器(如gdb)单步执行程序,我们会看到一系列的程序计数器的值,这些值对应着exe文件中的指令或者共享库中的指令。我们把这个PC值的序列叫做逻辑控制流。
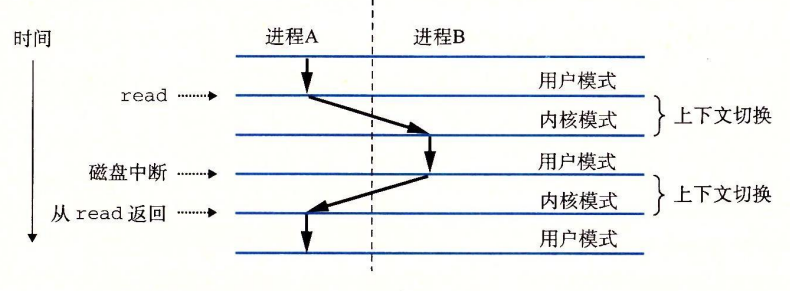
假设我们有一个运行着三个进程的系统,如下图所示:
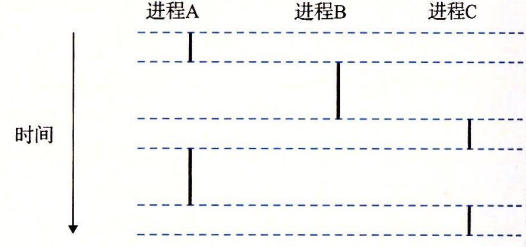
可以看到,实际上三个进程轮流地使用处理器,每个进程执行它的流的一部分,然后被抢占(preempted,暂时挂起),然后轮到其它进程。
如果一个逻辑流的执行在时间上与另一个流重叠,称为并发流(concurrency flow)。以上图为例,我们可以说A与B、A与C都是并发地运行的,而B与C并不是并发地运行,因为在B进程执行完成后,C进程才开始执行。
像这样多个流并发地执行的现象被称为并发(concurrency),一个进程与其它进程轮流运行的概念叫做多任务(multitasking)。一个进程被切分为多个时间片(time slice),因此多任务也叫做时间分片(time slicing)。
并发(concurrency)与并行(parallelism)的区别:
并发是指一个处理器同时处理多个任务。
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。
进程地址空间
在一台n位地址的机器上,地址空间是$2^n$个可能地址的集合。进程为每一个程序提供它自己的私有地址空间。一般而言,和这个空间中某个地址相关联的那个内存字节是不能被其他进程读或者写的,所以从这个意义上来说,这个地址空间是私有的。
每个x86-64进程的Linux私有地址空间都有这样的结构:
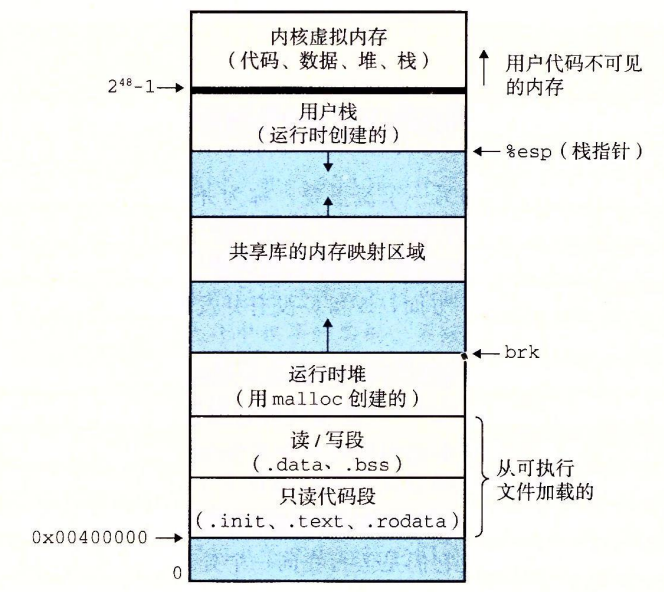
地址空间底部是保留给用户程序的,包括通常的代码、数据、堆和栈段。代码段总是从地址0x400000开始。
栈(Stack):
- 栈的起始地址靠近用户空间的高位地址,并向下增长。
- 栈用于保存局部变量、函数调用的返回地址以及函数参数等。
共享库和内存映射区域(Shared Libraries / Memory Mapped Region):
- 位于栈下方,用于映射动态链接库(如
libc.so)和文件或设备映射。 - 应用程序可以使用
mmap()系统调用来映射文件到该区域。
堆(Heap):
- 堆用于动态分配内存,位于BSS段之后。堆的起始地址位于数据段的下方,向上增长。
- 程序通过
malloc()、free()等函数对堆内存进行管理。
未初始化数据段(BSS段):
- 存放未初始化的全局变量和静态变量。
数据段(Data Segment):
- 存放已初始化的全局变量和静态变量。
代码段(Text Segment):
- 存放程序的可执行代码。
- 代码段通常是只读的,防止程序修改自己的代码。
同时,范围为0xffff800000000000到0xffffffffffffffff是内核空间,它用于操作系统内核的代码和数据。内核空间通常只有操作系统内核本身及其模块可以访问,普通用户进程无法直接访问此部分,以避免非法操作。
内核空间主要包含:
- 内核代码段:用于存储内核的可执行代码。
- 内核数据段:用于存储内核的全局变量和静态数据。
- 设备内存映射:用于内存映射设备驱动和I/O设备的内存。
- 内核栈:每个内核线程都有自己的内核栈,用于处理系统调用和异常处理。
处理器提供了一个模式位,当其被设置时,进程运行在内核模式中,可以访问任何指令以及任何内存位置。
上下文切换
内核为每一个进程维持一个上下文(context),记录了通用目的寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈和各种内核数据结构,比如页表、进程表、文件表等。
在进程执行的某些时刻,内核可以决定抢占当前进程,并重新开始一个先前被抢占的进程。这种决策称为调度,是由一个内核中称为调度器(scheduler)的代码处理的。切换进程通过切换上下文机制进行,其包括:1)保存当前进程的上下文;2)恢复先前进程的上下文;3)将控制转移给新的进程。
上下文切换通常发生在等待某个事件发生的阻塞时间。例如我们需要执行read指令读取磁盘中的数据,在等待磁盘读取数据时,内核会先切换进程,而不是什么都不做地等待。
进程控制
Unix提供了大量C程序中操作进程的系统调用。我们将学习一些重要的函数和使用方法。
获取PID
每一个进程都有一个唯一的正数进程ID(PID)。getpid函数返回调用进程的PID,getppid函数返回父进程的PID。
1 | |
pid_t类型被定义为int。
创建和终止进程
进程总是处于下面三种状态之一:运行/停止/终止。
通过exit(int status)函数,我们可以以status状态来结束进程。
父进程可以使用fork()函数来创建一个子进程。
1 | |
新创建的子进程和父进程之间最大的区别在于PID不同,而子进程的用户级虚拟地址空间与父进程相同,即代码、数据段、堆、共享库等等都一致。
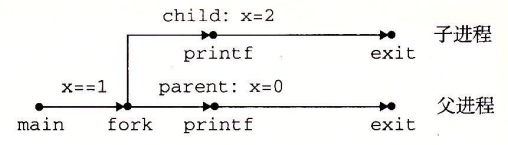
fork函数调用一次,返回两次。在父进程中,函数返回的是子进程的PID(如果出错会返回-1),而在子进程中返回0.这是为了区别是程序在子进程中执行还是在父进程中执行,因为子进程会复制父进程的相同代码。
下面看一个例子:
1 | |
执行代码,得到:
1 | |
父进程和子进程不共享内存: 父进程和子进程不会共享彼此的变量,除非通过特定的进程间通信(如共享内存或管道)来实现。每个进程都有自己的私有内存空间,子进程继承了父进程的变量,但它们在内存中的地址是不同的。
变量 x 的地址: 在父进程和子进程中,变量 x 在各自的地址空间中占据不同的物理地址,尽管在它们各自的虚拟地址空间中 x 可能具有相同的虚拟地址。
因此,在两个进程中,x是独立的。我们可以用进程图来表示:
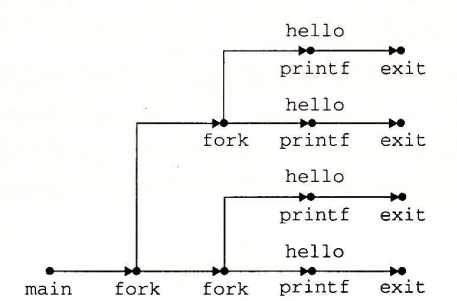
进程图也可以很方便的表示嵌套fork():
1 | |
回收子进程
当进程由于某种原因终止时,内核并不会立即将其从系统中清楚,相反,进程被保持在一种已终止的状态中直到被其父进程回收(reaped)。一个终止了但未被回收的进程称为僵死进程(zombie)。