T5
Introduction
T5 的基本思想是将每个 NLP 问题都视为“text-to-text”问题,即将文本作为输入并生成新的文本作为输出,这允许将相同的模型、目标、训练步骤和解码过程,直接应用于每个任务。
模型和框架称为 “Text-to-Text Transfer Transformer”——T5。
Embedding
T5模型的结构基于传统Transformer模型。
但Transformer 使用正余弦函数的位置编码,BERT 使用的是学习到的位置嵌入,而本文使用的是相对位置嵌入。
相对位置嵌入不是对每个位置使用固定的嵌入,而是根据 self-attention 机制中的“key”和“query”之间的偏移量生成不同的学习嵌入。T5将(key和query)相对位置的数值加在attention softmax之前的logits上,每个head的有自己的position embeddings,所有的层共享一套position embeddings,每一层都计算一次,让模型对位置更加敏感。
预训练过程
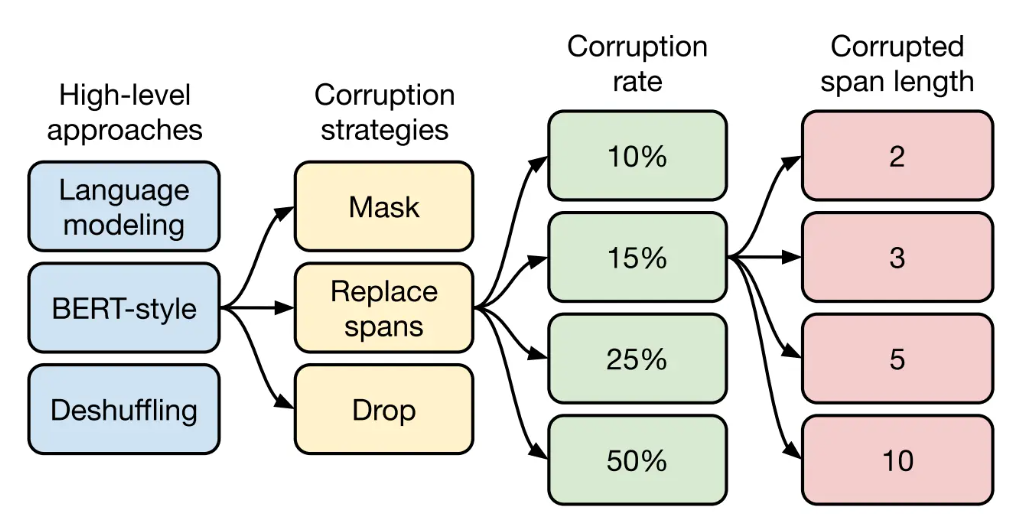
高层次方法(自监督的预训练方法)对比
语言模型式,类 GPT-2 方式,从左到右预测
BERT-style式,就是像BERT一样将一部分给破坏掉,然后还原出来,其效果最好
Deshuffling(顺序还原)式,就是将文本打乱,然后还原出来
掩码策略
Mask法,如现在大多模型的做法,将被破坏token换成特殊符如[M]
Replace span法,可以当作是把上面 Mask 法中相邻 [M] 都合成了一个特殊符,每一小段替换一个特殊符,提高计算效率,其效果最好
Drop法,没有替换操作,直接随机丢弃一些字符
对文本进行多大程度的破坏
挑了 4 个值:10%,15%,25%,50%,最后发现 BERT 的 15%效果最好
Replace Span
需要决定对大概多长的小段进行破坏,于是对不同长度进行探索:2,3,5,10这四个值,最后发现3效果最好。
训练结论
- Architectures
原始的Transformer结构表现最好
encoder-decoder结构和BERT、GPT的计算量差不多
共享encoder和decoder的参数没有使效果差太多
- Unsupervised objectives
自编码和自回归的效果差不多
推荐选择更短目标序列的目标函数,提高计算效率
- Datasets
在领域内进行无监督训练可以提升一些任务的效果,但在一个小领域数据上重复训练会降低效果
Large、diverse的数据集效果最好
- Training strategies
精调时更新所有参数 > 更新部分参数
在多个任务上预训练之后微调 = 无监督预训练
- Scaling
在小模型上训练更多数据 < 用少量步数训练更大的模型
从一个预训练模型上微调多个模型后集成 < 分开预训练+微调后集成
模型结构
1 | |
参考: