BERT
BERT简述
BERT的全程为 Bidirectional Encoder Representation from Transformers ,是一个基于 Transformer 模型的预训练语言表征模型。
BERT强调不再采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的 masked language model(MLM) 以生成深度的双向语言表征。
BERT的结构
以往的预训练模型的结构会受到单向语言模型(从左到右或者从右到左)的限制,因而也限制了模型的表征能力,使其只能获取单方向的上下文信息。
而BERT利用MLM进行预训练并且采用深层的双向Transformer组件来构建整个模型,最终能够生成融合左右上下文信息的深层双向语言表征。
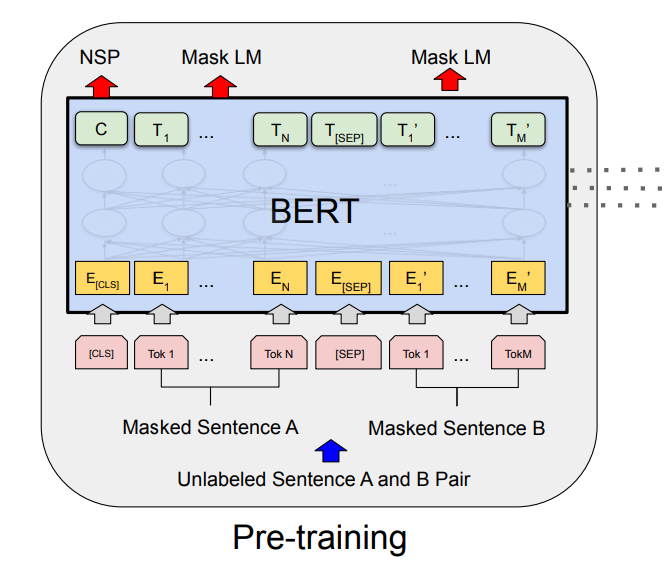
输入结构
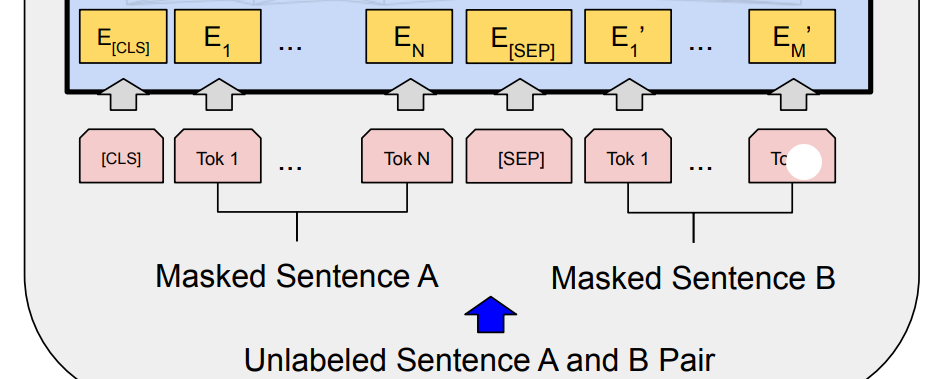
BERT的输入为每一个token对应的表征(图中的粉红色块就是token,黄色块就是token对应的表征),并且单词字典是采用 WordPiece 算法来进行构建的。
为了完成具体的分类任务,除了单词的token之外,作者还在输入的每一个序列开头都插入特定的分类token([CLS]),该分类token对应的最后一个Transformer层输出被用来起到聚集整个序列表征信息的作用。
分辨哪个范围是属于句子A,哪个范围是属于句子B呢?BERT采用了两种方法去解决:
在序列tokens中把分割token([SEP])插入到每个句子后,以分开不同的句子tokens。
为每一个token表征都添加一个可学习的分割embedding来指示其属于句子A还是句子B。
[CLS] token:
CLS token 是 “Classification” token 的缩写,它位于每个输入句子的开头。这个 token 的主要作用是为句子的分类任务提供一个整体的句子表示。在训练过程中,通常会将这个 token 的输出作为整个句子的表示,然后将它输入到分类器中进行分类。
[SEP] token:
SEP token 是 “Separation” token 的缩写,它用于分隔两个句子或者文本片段。在输入句子或文本片段之间需要插入一个 SEP token,以帮助模型更好地理解它们之间的关系。这对于BERT的双句子任务(如句对分类、问答等)是非常重要的。
对于每个Token对应的表征,我们将其分为三部分,分别是对应的Token,分割和Position Embeddings
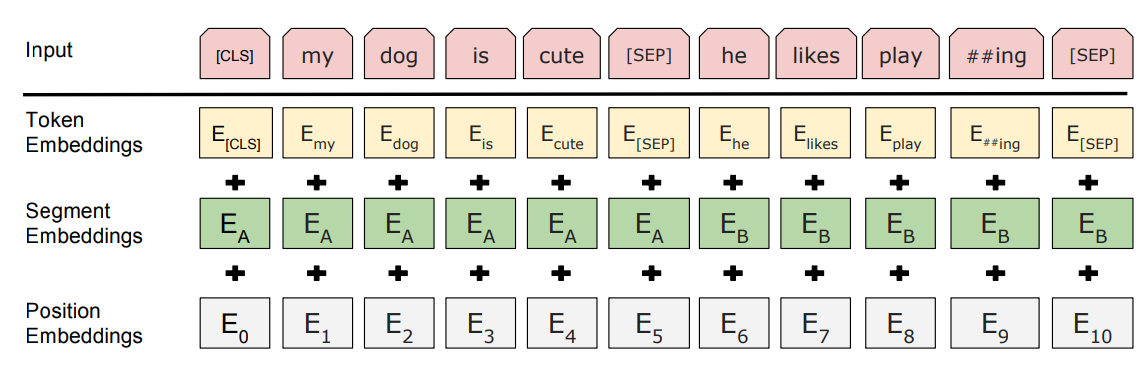
此处的position embedding和Transformer模型中的一致,由公式给出:
$$ PE_{(pos,2i)} = sin(pos / 10000^{2i / d})$$
$$ PE_{(pos,2i+1)} = cos(pos / 10000^{2i / d})$$
在BERT模型中,位置嵌入是通过以下步骤生成的:
位置编码矩阵生成
首先,BERT模型学习一个位置编码矩阵,其维度为 $\text{max_seq_length} \times \text{embedding_size}$ ,其中 $\text{max_seq_length}$ 是输入序列的最大长度, $\text{embedding_size}$ 是词嵌入的维度。位置编码计算
对于输入序列中的每个位置 $pos$ 和每个维度 $i$,位置嵌入 $PE(pos, i)$ 计算如下:
$$
[
PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right)
]
[
PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right)
]
$$
其中,$pos$ 是位置,$i$ 是维度, $d_{\text{model}}$ 是词嵌入的维度。位置嵌入向量获取
对于输入序列中的每个词(或子词),通过位置编码矩阵中对应位置的值来获取位置嵌入向量。位置嵌入与词嵌入相加
将位置嵌入向量与词嵌入向量相加,得到最终的输入向量。
Encoder
从图中我们可以看出,BERT采用双向Encoder进行连接,舍弃了Decoder部分。
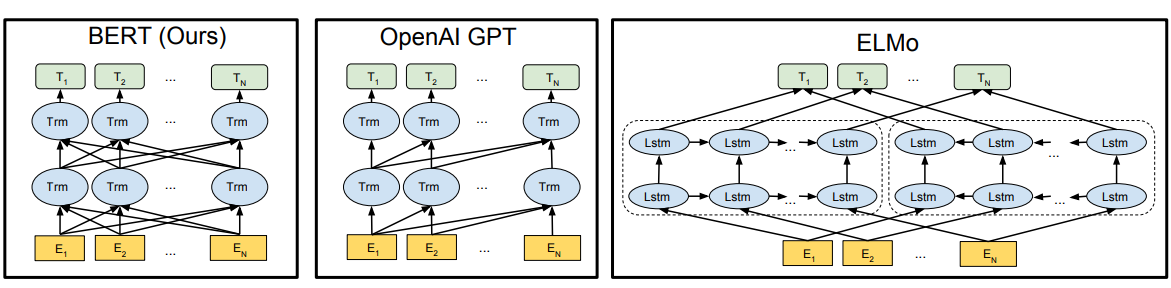
最后呈现的输出为:
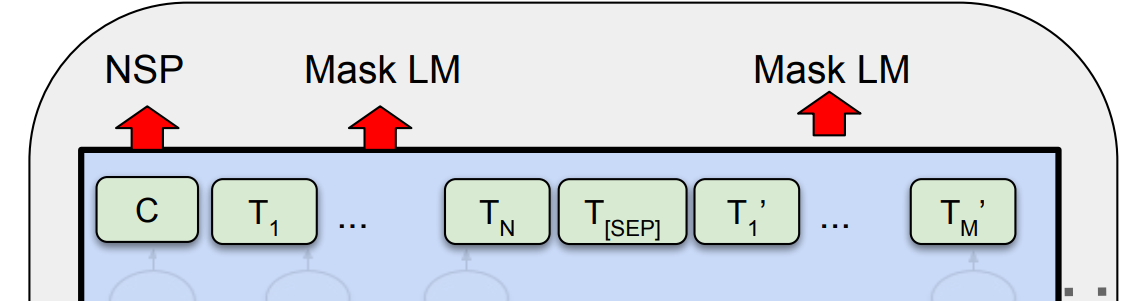
$C$ 为分类token([CLS])对应最后一个Transformer的输出, $T_{i}$ 则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务(如,序列标注和问答任务),就 $T_{i}$ 把输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把 $C$ 输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
BERT的预训练任务
BERT构建了两个预训练任务,分别是 Masked Language Model 和 Next Sentence Prediction
Masked Language Model(MLM)
MLM是BERT能够不受单向语言模型所限制的原因。简单来说就是以15%的概率用mask token ([MASK])随机地对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有的单词。然而,由于[MASK]并不会出现在下游任务的微调(fine-tuning)阶段,因此预训练阶段和微调阶段之间产生了不匹配(这里很好解释,就是预训练的目标会令产生的语言表征对[MASK]敏感,但是却对其他token不敏感)。因此BERT采用了以下策略来解决这个问题:
首先在每一个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第i个token被选中,则会被替换成以下三个token之一
80%的时候是[MASK]。如,my dog is hairy——>my dog is [MASK]
10%的时候是随机的其他token。如,my dog is hairy——>my dog is apple
10%的时候是原来的token(保持不变)。如,my dog is hairy——>my dog is hairy
再用该位置对应的 $T_{i}$ 去预测出原来的token(输入到全连接,然后用softmax输出每个token的概率,最后用交叉熵计算loss)。
Next Sentence Prediction
在NLP中有一类重要的问题比如QA(Quention-Answer), NLI(Natural Language Inference), 需要模型能够很好的理解两个句子之间的关系, 从而需要在模型的训练中引入对应的任务. 在BERT中引入的就是Next Sentence Prediction任务。采用的方式是输入句子对(A, B), 模型来预测句子B是不是句子A的真实的下一句话。
所有参与任务训练的语句都被选中作为句子A。
其中50%的B是原始文本中真实跟随A的下一句话. (标记为IsNext, 代表正样本)
其中50%的B是原始文本中随机抽取的一句话. (标记为NotNext, 代表负样本)
在任务二中, BERT模型可以在测试集上取得97%-98%的准确率。
补充:NLP三大Subword模型
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。
这种方法构造的词表存在着如下的问题:
实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将无法处理及生成
词表中的低频词/稀疏词在模型训练过程中无法得到充分训练,进而模型不能充分理解这些词的语义
一个单词因为不同的形态会产生不同的词,如由”look”衍生出的”looks”, “looking”, “looked”,显然这些词具有相近的意思,但是在词表中这些词会被当作不同的词处理,一方面增加了训练冗余,另一方面也造成了大词汇量问题
Byte Pair Encoding (BPE)
BPE获得Subword的步骤如下:
- 准备足够大的训练语料,并确定期望的Subword词表大小;
- 将单词拆分为成最小单元。比如英文中26个字母加上各种符号,这些作为初始词表;
- 在语料上统计单词内相邻单元对的频数,选取频数最高的单元对合并成新的Subword单元;
- 重复第3步直到达到第1步设定的Subword词表大小或下一个最高频数为1.
下面以例子说明。假设我们有这样一个语料:{‘low’:5,’lower’:2,’newest’:6,’widest’:3}
其中数字代表对应单词的出现频数。
- 拆分单词成最小单元,并初始化词表。这里,最小单元为字符,因而,可得到

需要注意的是,在将单词拆分成最小单元时,要在单词序列后加上“”(具体实现上可以使用其它符号)来表示中止符。在子词解码时,中止符可以区分单词边界。
- 在语料上统计相邻单元的频数。这里,最高频连续子词对”e”和”s”出现了6+3=9次,将其合并成”es”,有

由于语料中不存在’s’子词了,因此将其从词表中删除。同时加入新的子词’es’。一增一减,词表大小保持不变。
- 继续统计相邻子词的频数。此时,最高频连续子词对”es”和”t”出现了6+3=9次, 将其合并成”est”,有

- 继续上述迭代直到达到预设的Subword词表大小或下一个最高频的字节对出现频率为1
从上面的示例可以知道,每次合并后词表大小可能出现3种变化:
- +1,表明加入合并后的新子词,同时原来的2个子词还保留(2个字词分开出现在语料中)。
- +0,表明加入合并后的新子词,同时原来的2个子词中一个保留,一个被消解(一个子词完全随着另一个子词的出现而紧跟着出现)。
- -1,表明加入合并后的新子词,同时原来的2个子词都被消解(2个字词同时连续出现)。
在得到Subword词表后,针对每一个单词,我们可以采用如下的方式来进行编码:
- 将词典中的所有子词按照长度由大到小进行排序;
- 对于单词w,依次遍历排好序的词典。查看当前子词是否是该单词的子字符串,如果是,则输出当前子词,并对剩余单词字符串继续匹配。
- 如果遍历完字典后,仍然有子字符串没有匹配,则将剩余字符串替换为特殊符号输出,如”
”。 - 单词的表示即为上述所有输出子词。
解码过程比较简单,如果相邻子词间没有中止符,则将两子词直接拼接,否则两子词之间添加分隔符。
WordPiece
与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
我们假设句子 $S=(t_{1}, t_{2}, \ldots , t_{n})$ 由 $n$ 个子词组成,各子词独立存在,则句子 $S$ 的语言模型似然值等价于所有子词概率的乘积:
$$\log{}{P}(S)=\sum_{i=1}^{n}\log{}{P}(t_{i})$$
假设把相邻位置的 $x$ 和 $y$ 两个子词进行合并,产生子词 $z$ ,那么此时句子 $S$ 的似然值可以表示为:
$$\log{}{P}(t_{z})-(\log{}{P}(t_{x})+\log{}{P}(t_{y}))=\log{}{\frac{P(t_{z})}{P(t_{x}P(t_{y}))}}$$
似然值的变化就是两个子词之间的互信息。WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
互信息(Mutual Information)是一种用于衡量两个事件之间相关性的统计指标,它可以用来衡量两个随机变量之间的信息共享程度。在WordPiece算法中,可以使用互信息来衡量两个相邻的子词单元之间的关联程度,以帮助决定是否将它们合并。
互信息的计算公式如下:
$$I(X;Y) = \sum_{x \in X} \sum_{y \in Y} p(x,y) \log \left( \frac{p(x,y)}{p(x)p(y)} \right)$$
Unigram Language Model (ULM)
Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
参考: