文本预处理
文本预处理以及其作用
文本语料在输送给模型前一般需要一系列的预处理工作,才能符合模型输入的要求,如:将文本转化成模型需要的张量,规范张量的尺寸等,而且科学的文本预处理环节还将有效指导模型超参数的选择,提升模型的评估指标。
文本预处理中包含的主要环节
- 文本预处理的基本方法
- 文本张量表示方法
- 文本语料的数据分析
- 文本特征处理
- 数据增强方法
我们主要针对中文和英文进行处理
1.文本预处理的基本方法
分词
https://github.com/fxsjy/jieba
jieba库可以帮助我们对句子进行切分,作为Tokenizer使用。
- 精确模式:将句子最精确的切开(cut_all = False)
1 | |
输出结果如下:
1 | |
- 全模式分词:把句子中所有可以成词的词语都扫描出来,速度快但会产生歧义。
将变量 cut_all = Ture ,输出下面结果:
1 | |
- 搜索引擎模式分词:对长词再次切分,提高召回率。
1 | |
输出结果如下:
1 | |
- 使用用户自定义词典:
- 添加自定义词典后,jieba能够准确识别词典中出现的词汇,提升整体的识别准确率
- 词典格式:每一行分为三部分(词语,词频,词性,用空格隔开,顺序不可换)
流行中英文分词器hanlp
- 中英文NLP处理工具包,基于tensorflow2.0,使用在学术和行业中推广最先进的深度学习技术
1 | |
命名实体的识别
对句子进行切分之后,我们可以进行命名实体的识别
命名实体:通常我们将人名、地名、机构名等专有名词统称为命名实体。命名实体识别(Named Entity Recognition)就是识别出一段文本中可能的命名实体。
命名实体是人类理解文本的基础单元,也是AI解决NLP领域高阶任务的重要基础环节。
我们可以使用hanlp进行中文命名实体的识别。
1 | |
词性标注(Part-Of-Speech tagging)
- 词性标注以分词为基础,是对文本语言的另一个角度的理解,也常常称为AI解决NLP领域的高阶任务的重要基础环节。
使用jieba进行中文词性标注:
1 | |
输出结果:
1 | |
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
2.文本张量表示方法
文本张量表示:讲一段文本使用张量进行表示,其中一般词汇表示成向量,称为词向量,再由各个词向量按顺序组成矩阵形成文本表示。
例子:[“学历”,”是”,”我”,”下不来的”,”高台”]
==> [[1.32, 4.11, 2.33],
[5.32, 6.11, 2.53],
[1.22, 4.16, 2.83],
[8.32, 6.61, 2.83],
[8.62, 4.71, 2.73]]
文本张量表示的方法
- one-hot编码
One-hot编码是将每个词或字符映射到一个唯一的整数索引,然后创建一个向量,长度与词汇表大小相同,所有元素为0,除了对应索引处的元素为1。例如,假设我们有一个词汇表包含4个词:[“apple”, “banana”, “orange”, “grape”],则每个词可以被编码为:
apple: [1, 0, 0, 0]
banana: [0, 1, 0, 0]
orange: [0, 0, 1, 0]
grape: [0, 0, 0, 1]
One-hot编码的优点是简单直观,并且不会引入任何语义相关性。然而,它也存在一些缺点,比如编码的向量维度很大,且无法捕捉词汇之间的语义相似性。
one-hot编码实现
1
2
3
4
5
6
7
8
9
10
11
12
13form sklearn.externals import joblib
form keras.preprocessing.text import Tokenizer
vocab = {}
t = Tokenizer(num_words = None, char_level=False)
t.fit_on_texts(vocab)
for token in vocab:
zero_list = [0]*len(vocab)
token_index = t.texts_to_sequences([token])[0][0] - 1
zero_list[token_index] = 1
# 保存
tokenizer_path = "./Tokenizer"
joblib.dump(t, tokenizer_path)one-hot编码使用
1 | |
- Word2vec
Word2Vec是一种词嵌入技术,它能够将词汇映射到一个连续的低维向量空间。
Word2Vec模型通过学习大量文本语料库中的上下文信息来产生这些向量。其核心思想是:在一个窗口内,一个词的上下文可以帮助我们理解这个词的含义。
Word2Vec生成的词向量具有一定的语义关系,即在向量空间中相似的词在语义上也是相似的。例如,通过Word2Vec训练得到的词向量,可以通过计算向量之间的距离来找出语义上相似的词。
Word2Vec模型有两种主要的架构:连续词袋(CBOW)和Skip-gram。
- CBOW(Continuous Bag of Words):通过上下文词预测目标词。
CBOW在给定的一段文本语料中选调某段长度
(窗口)
作为研究对象,使用上下文词汇进行预测.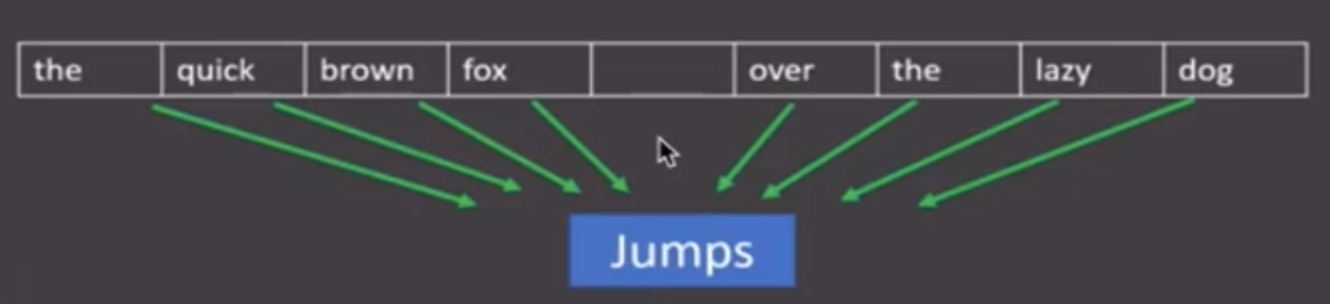
分析:图中窗口大小为9,使用前后4个词汇预测中心词。
CBOW模型的工作原理:
输入层:CBOW模型的输入层接收由上下文词汇表示的One-hot编码。假设我们使用窗口大小为2的上下文,对于给定的目标词汇,上下文词汇包括其左右两个词汇。
投影层:输入的One-hot编码经过一个投影层,将每个One-hot编码映射到一个连续的低维向量空间,即词向量空间。
合并层:合并层将所有上下文词汇的词向量进行平均或求和,得到一个表示上下文信息的向量。
输出层:合并后的上下文向量通过输出层进行预测,输出层是一个softmax分类器,用于预测词汇表中每个词汇的概率分布。最终,模型选择概率最高的词汇作为预测的目标词汇
假设我们有一个简单的语料库:”The cat sat on the mat.”
输入:“The”、“sat”、“the”、“on” 的One-hot编码。
投影层:将上述词汇的One-hot编码映射到词向量空间。假设我们的词向量维度为3,每个词汇的向量表示如下:
“The”:[0.2, 0.3, 0.1]
“sat”:[-0.1, 0.2, 0.4]
“the”:[0.3, -0.1, 0.2]
“on”:[0.4, 0.1, -0.3]
合并层:将所有上下文词汇的词向量进行平均或求和。假设我们将它们求和,得到合并后的上下文向量为:[0.8, 0.5, 0.4]。
输出层:利用合并后的上下文向量,通过softmax分类器预测目标词汇的概率分布。例如,预测 “cat” 的概率为0.6,”dog” 的概率为0.3,”apple” 的概率为0.1。则模型将选择概率最高的词汇 “cat” 作为预测的目标词汇。
- Skip-gram:通过目标词预测上下文词。
Skip-gram模型是Word2Vec中的一种模型,与CBOW模型相反,它的核心思想是根据目标词来预测上下文词,通过学习到的词向量来捕捉词汇之间的语义关系。
结构模型:
输入层:Skip-gram模型的输入是目标词的One-hot编码。
投影层:输入的One-hot编码经过一个投影层,将每个One-hot编码映射到一个连续的低维向量空间,即词向量空间。
输出层:投影后的目标词汇向量通过输出层,输出的是上下文词汇的概率分布。对于给定的目标词汇,Skip-gram模型试图学习到一个概率分布,使得给定目标词汇的情况下,其周围上下文词汇出现的概率最大化。输出层是一个softmax分类器,用于预测词汇表中每个词汇的概率分布。
假设我们有一个简单的语料库:”The cat sat on the mat.”
输入:“cat” 的One-hot编码。
投影层:将目标词汇的One-hot编码映射到词向量空间。假设我们的词向量维度为3,每个词汇的向量表示如下:
“cat”:[0.2, 0.5, -0.1]
- 输出层:利用投影后的目标词汇向量,通过softmax分类器预测周围上下文词汇的概率分布。例如,预测 “The” 的概率为0.6,”sat” 的概率为0.3,”mat” 的概率为0.1。则模型将选择概率最高的词汇作为上下文词汇的预测结果。
- Word Embedding
Word Embedding是一种将词汇映射到实数向量的技术.
广义的word embedding包括所有密集词汇向量的表示方法,狭义的word embedding指在神经网络中加入embedding层,对整个网络进行训练的同时产生的embedding矩阵。
使用fasttext工具实现word2vec的训练和使用
- 获取训练数据
- 训练词向量
- 模型超参数设定
- 模型效果检验
- 模型的保存与重加载
获取训练数据
在这里,我们研究 Wikipedia 的部分网页信息。
下载数据:
1 | |
原始数据处理:我们需要将html语言中无用的符号去除。
这里我们使用fasttext中的Perl脚本Wikifil.pl
1 | |
训练词向量
代码直接在解释器中运行。
1 | |
模型超参数设定
- 训练模式:无监督训练分为’skipgram’和’chow’,默认为前者
- 词嵌入维度dim:默认为100
- 数据循环次数epoch:默认为5
- 学习率lr:默认为0.05
- 线程数thread:默认为12个线程,建议与CPU核数相同
模型效果检验
1 | |
模型的保存与重加载
1 | |
3.文本数据分析
文本数据分析的作用:文本数据分析能够有效帮助我们理解数据语料,快速检查出语料可能存在的问题,并指导之后模型训练过程中一些超参数的选择。
常用的几种文本数据分析方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词词云
4.文本特征处理
文本特征处理的作用:为语料添加具有普适性的文本特征,如n-gram特征,以及对加入特征之后的文本语料进行必要的处理,如长度规范。这些特征处理工作能够有效的将重要的文本特征加入模型训练当中,增强模型评估指标。
- n-gram特征:给定一段文本序列,其中n个词或字的相邻共现特征即n-gram特征。
常用的n-gram特征是bi-gram和tri-gram,对应n为2和3
- 文本长度规范:一般模型的输入需要等尺寸大小的矩阵,因此在进入模型前需要对每条文本数值映射后的长度进行规范,此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度,对超长文本进行截断,对不足文本进行补齐。
5.文本数据增强
关于回译数据增强法:回译数据增强指将文本数据翻译成另外一种语言,之后再翻译回原语言,就得到了同标签的新语料,将这个新语料加入原数据集中即可认为是数据增强。
1 | |